ちょっと昔まではデータ基盤の管理人・アーキテクト, 現在は思いっきりクラウドアーキを扱うコンサルタントになったマンです.
私自身の経験・スキル・このブログに書いているコンテンツの関係で,
- 「データ基盤って何を使って作ればいいの?」的なHow(もしくはWhere)の相談.
- 「Googleのビッグクエリーってやつがいいと聞いたけど何ができるの?」的な個別のサービスに対するご相談.
- 「ぶっちゃけおいくらかかりますか💸」というHow much?な話.
有り難くもこのようなお話をよくお受けしています.
が, (仕事以外の営みにおける)個人としては毎度同じ話をするのはまあまあ疲れるので,
データ基盤にありがちな「何を使って作ればよいか?」という問いに対する処方箋
というテーマで,
- クラウド上でデータ基盤を構築する際のサービスの選び方
- (データ基盤に限らず)クラウド料金の基本的な考え方
をGoogle Cloudを例にして書きたいと思います.
なお, 本コンテンツは以下の項目で構成されています.
免責事項
テーマ的に色んな期待値を持たれている方が読むと思うので免責事項およびスコープをここに明記します.
このコンテンツの立ち位置
当記事は所属企業・団体(含む取引先)の活動・考えとは無関係な個人の見解・考えを記載したものとなっております.
もっと雑に言うと, 「自分の経験から基づいたポエムです, 仕事とは関係ないよ」っていう話です.
また, 例はGoogle Cloudですが, AWSやAzure等のパブリッククラウドで通用する最大公約数的な話を目指して執筆しています.
微妙なサービス・クラウドの仕様の違いはありますが, 他のクラウドを使ってる方は読み替えてやってもらえるといいかもです&文章中では可能な限りAWSにおけるサービスの解説も加えておりますかつ, 私個人の好みはGoogle Cloudですが, 「必ずGoogleを使いなさい」という回し者ではないことだけ明言しておきます.
範囲(スコープ)と用語
データ基盤の要件定義で「さあ何をどう作ろう?」みたいなフェーズにおける技術選定・見積もりで役に立つ話, ぐらいの範囲でお話します.
- データ基盤の必要性・意味や意義
- データ保存・管理の考え方
- 組織の考え方・教育・利用の推進
といった「データ基盤・データ整備人および利活用の云々」についてはこのエントリーのスコープ外となりますので,



この辺の書籍や, 各企業のテックブログ・発表等をご覧いただくことをオススメします.
上記に加え, 各クラウドサービスやツール, Frameworkといった解説はしませんのでご了承ください(気になる方はググってください).
また, 特に断りが無い限り,
- データ基盤・活用に関する専門用語は「実践的データ基盤への処方箋」に合わせています.
- Google Cloudに関しては公式のドキュメントの用語を利用, アイコンは公式のアイコンセットを使っています.
文中の用語と絵はこのようなルールで執筆しています.
TL;DR
- 各サービス・ソフトウェアの特徴と使い方を知った上で役割に合わせて選択しましょう.
- 料金は「保管コスト(量と時間)」「データの流量」「コンピュータ資源の利用状況」で決まるのが原則, あなた自身のユースケース次第でなんぼでも変わります.
全体像
いきなり説明に入る前に, このブログで話したい事をエイヤッとお絵かきしてみました.

データ基盤を構成するサブシステム(コンポーネント)には以下の役割があります.
- システムのログ・データ, Webサイトやスマホ, アプリから出てくる何かをひたすら収集するデータ収集. 結果は生データ(Raw Data)置き場であるDatalake(データレイク)に保管される
- 生データ(Raw Data)を解析・整形し, SQLなどの操作言語で処理できる状態にするためのデータウェアハウス(DWH)生成(上の図ではDatalake->DWHの部分). 処理されたデータは分析用データの保管先であるDWHに保存される.
- BI Toolやアプリケーションといったユースケースから使う, 整形済みのデータ(カタログだったりテーブルだったりする)はDatamart(データマート)と呼ばれるデータとして保管する. DatamartはDWHから生成する(データマート生成, 上の図ではDWH->Datamartが該当).
- データ収集から各データの生成といったタスク管理(一連のバッチ処理みたいなもの)を司るコンポーネントとしてワークフロー(ワークフローエンジン)が存在する.
- これはパブリッククラウド限定の話になるが, 「データ収集・前処理から機械学習モデル生成・デプロイ」といった一気通貫に行うサービスが存在する(上の図で言うところのAI/Row Code系)」具体的なサービスとしてはGoogle CloudのAI Platform, AWSのSagemakerなど.
私はこの手の話をするときは相手と目線を揃えるため, 「どこの領域・コンポーネントの話なのか?」から先にするようにしています*1, 理由は明確で「コンポーネントが違うとサービス選びの視点が違ってくる」からです(意訳・全部が全部BigQuery入れたらおしまい, ではなくて総合的に考える必要がある) .
何を使えばいいか?
というわけで, コンポーネント別にサービスなどを挙げていきます.
データ収集
まずいきなりですが, エンジニアリング的にはここが最もハマりどころかつ難しいんじゃないかなと思っています.
観点として,
- データを相手から受け取る(相手からpushしてもらうのを受ける) or 取りに行く(データ基盤側からpullする)
- 受け取る: 指定した場所(Storage, sftp serverなど)にdumpしておいてもらう, データ基盤側でAPIコールできるようなインターフェースを用意する(データを持ってる側がAPIをコールする), etc...
- 取りに行く: 相手のDatabaseやStorageに繋いで取りに行く, 相手のAPIをコールして取得する, etc...
- 取るタイミング*2
- 定期的な処理(毎日, 毎時等のタイミング)
- 不定期な処理(データのdumpやアーカイブを取得して取り込む等)
- イベント駆動(APIを呼ぶ, ファイルを置く等のイベントで取り込みなど. ストリーミングもこの類になる)
- データの種類・型
他にもいくつか視点があるかもしれません, ホントややこしいです.
私の選び方の観点ですが,
- データを受け取る or 取りに行く(pushかpullか)を見極める. 例えば日時のバッチであれば「こちらから取りに行く」アプローチかもしれませんし, 「生ログをひたすら貯める」みたいなスタイルだと「ログを受け取るエントリーポイントを用意して相手に投げてもらう」かもしれません&これの違いは結構あります.
- タイミングの明確化. 一般的には「イベント駆動 > 定期的な処理 > 不定期な処理」で難易度が変わる(イベント駆動が一番難しい*3)のと, 「定期的な処理でいいものをイベント駆動で作る」みたいなのは辛い時もあるのでここも見極める.
- データ型やフォーマットに合わせて最も適切なサービス・ツールを選択する(かつ, フルスクラッチで作るのは最終手段であると心得る). 例えばJSONやCSV, Databaseを相手にします, だと自前で作らなくても良いサービスがある可能性があります.
だいたいこの辺から考えます, メンテナンスを考えるとなるべく自分でアプリを作らなくて良い手段が良いとも思っています.*4
Google Cloudの場合,
- 生ログなどをストリーミングしてStorageに保存したい!だとDataflowが有力な選択肢に. ちなみに定期的なバッチ処理も行ける.
- RDBMSなどのオペレーショナルなデータベースからデータを取得するような収集であればCloud Data Fusionも選択肢に.
- システムの移行, ファイルの移動などで大量データの移送が必要な場合, Transfer Applianceを使うべきかもしれない.
- WebのAPIを叩いたり, 自前で何かしらのクローリング・スクレイピングが必要な場合, 自分でスクラッチしたアプリ(もしくはEmbulkを自前でホストするなど)をCloud RunやCloud Functionsで動かすことになるかもしれない.
こんな感じで考える事になるかと思います&ここに挙げた以外にも手段はたくさんあります.
データレイク
生データ(or最小限の加工をしたデータ)をひたすら貯める役割です.
視点としてはシンプルで,
- 適切な保管コストで貯めておくことができるStorage
- CSVやJSONといった構造型データであれば, コストを掛けずにSQLから操作できるようなDatabase(フェデレーションを使うのも有り)
これらを選べばまず間違いないかなと思います.
- ひたすら保管・貯めるStorageとしてのCloud Storage. AWSだとS3が該当.
- 外部データソースが使えるDatabaseとして, BigQuery. AWSだとAthenaとか.
データ収集のコンポーネントがひたすらデータを積み上げることができてかつ, 長期保存等のルールで保管コストが有利になるものを選ぶとまず間違いないかと.
DWHとデータマート
BIやアプリケーションから分析目的で使うデータがデータマート, その一歩手前の構造データだったり格納場所だったりするのがDWH.
ここは境界線が曖昧かつ, どっちも同じような要件なのでまとめて紹介します.
- SQLやそれに該当する操作言語で扱える
- BI Tool, 外部システムから扱うためのインターフェースや仕組みが存在する
この辺が条件だと思っていて, BigQueryやData Catalogがこの辺の用途とぴったりかなと(AWSだとRedshiftなど.).
ちなみにですが, 「別のデータソースをラッピングして利用者が使えるようになる」技術, いわゆる「フェデレーション」ができることも要件次第ではありますが必須条件になると思います.*5
DWH生成/データマート生成
インプットとなるデータから目的のデータを抽出・加工・出力するコンポーネントです.
- データレイクからデータを取得, 集計加工してDWHへ
- DWHのデータを何かしらの集計・加工してデータマートへ
データ系のエンジニアリングだとこのような処理をするコードを実装する機会が結構ありますよね.
ここはイベント駆動もしくはバッチ処理でのプログラムを作って動かすみたいなアプローチになるので,
- Cloud RunみたいなContainerベースの環境でデータ処理するアプリケーションを実装・運用. AWSだとECS, 特にFargateでやる鉄板パターン
- 軽い処理であればCloud Functionsで関数を実装. これもAWS Lambdaでよくやるパターンでもある.
こんな感じかなと.
また, 「ピボットテーブル的な事をして集計した結果を別テーブルに保存する」「ちょっとした前処理・クラスタリングをする」みたいなパターンだと, Apache Sparkが使えるサービスが活躍する舞台でもあります.
この辺も十分選択肢になるかと.
ワークフロー
データ収集やDWH, データマートの生成など別のコンポーネントをスケジュールと順序に従って動かすのがワークフローです.
個人的には「ピタゴラスイッチ」と呼んでいます(由来は察してください).
これの考え方は2つだと思っていて,
- Apache Airflowなどのオーケストレーションツール・Frameworkを使ってワークフローを制御する.
- スケジューラーやキューのサービスを組み合わせて自前でワークフローを作る.
Airflowを動かす前提だとCloud Composerや, Amazon MWAA(Managed Workflows for Apache Airflow).
スケジューラーやキューの組み合わせでの実現は,
- スケジューラーとしてCloud SchedulerやCloud Task
- キューとしてCloud Pub/Sub
などを作って自前で作るイメージとなります.
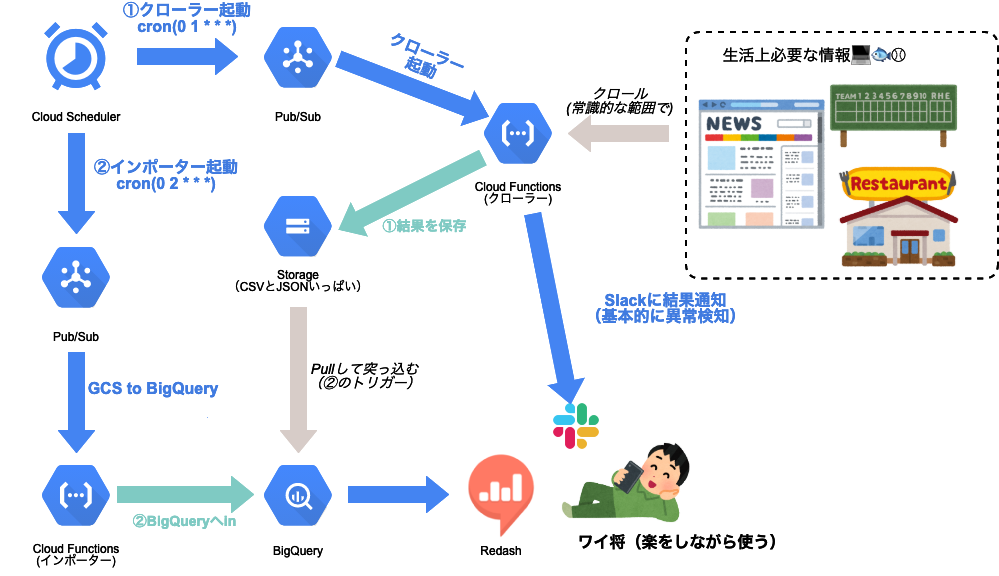
例えばこういう事ができます(例はデータ基盤ではありませんが, データ基盤でも同じ用に使えます).
ちなみにですが, 自前で作るときのメリット・デメリットですが,
- 自前で作るメリット(Airflowを使わない)
- 構築の自由度が高い. AirflowだとDAGやOperatorの仕様次第でハマる事がある(例えばOperatorそのものがない場合など)
- サーバレスアーキテクチャを全力で使えるためコストメリットが非常に高い. Airflowの場合, AirflowをホストするK8sクラスタやサーバーが必要
- デメリット
- 学習コスト. Airflowと互角かもしれないが, 「キューからのイベント駆動でファンクションを動かします」みたいな開発に慣れるまでのコストも中々かかる.
- 冪等性の担保, 運用上のリカバリといったケア. Airflowの仕組みに乗っかる場合はノウハウ・プラクティスが使えるが, 自前の場合は考えて設計しないと詰む.
こんな所かなと.
AI系の何か
ここまで紹介したコンポーネントは「組み合わせて使う」系が多かったですが,
- データの取得から前処理, 保存そしてデータ探索・以上検出などのタスクまで一気通貫にやる. 例としてはDataprepなど.
- 機械学習モデルの構築・デプロイ・運用まで一気通貫にやる. Vertex AI, AI Platform*6, Amazon SageMakerなど.
目的に合致していたら単体で使えるサービスもいくつかあります. 中身を知った上で使うといい感じになるのでこれらもオススメです.
料金の考え方
最後に大事なお金の話を.
料金の考え方ですが, 「保管コスト(量と時間)」「データの流量」「コンピュータ資源の利用状況」を観点として, 自動計算ツールで算出が最も近道 だったりします.
- データの保管には必ずお金がかかります. と言いつつも無料枠があったりするのでそのルールを活用するのと, Storageの場合は長期保存タイプを使うなどして最適なコストを計算できるとGood.
- 動いているアプリケーションでどれぐらいデータが流れるか, 平たく言えばネットワークの容量を取れば取るほどお金がかかります.
- CPU, メモリ, ディスクなどのコンピュータ資源をどれだけ使っているか. 使っていなくても, インスタンスを保持するだけでもお金がかかります. サーバレス系のサービスを使って「使ってる間だけリソースを割り当てる」などして圧縮可能.
これらを頭に入れつつ, 各社クラウドの計算ツールを使うのがいいと思います.
事例を聞いてコストを確認するのも悪くないですが, 最後は自分で計算(もしくは作って運用してからウォッチする)のが最もてっとり速いのでオススメです.
結び
ということで, 「データ基盤にありがちな「何を使って作ればよいか?」という問いに対する処方箋」についての考察・ポエムでした.
私はここに至るまでの知識・経験を得るまでいくつかのプロジェクト(個人開発を含む)を経験し, その中でいくつかの失敗をしました.
また, クラウドサービスを使う前提だと, 新機能・新サービスの発表だったりユースケースの変化で以前のやり方よりもっといいやり方が出てきたりもします.
おそらく, このブログの観点・ノウハウも2023年にはもうちょっと変わってる可能性があります.
中々追随するのが大変な分野ですがやってて面白い所でもあるので, 引き続き動向をウォッチしつつ手を動かして色々出来たらなと思います, 最後までお読みいただきありがとうございました!
*1:これは割と重要な話で例えば一言でBigQueryの相談と言っても, データレイク的に使うのかそれともデータマート的に使うのかで話の内容が変わってきます.
*2:リアルタイムと書くとややこしくなるので, あえて冗長な分け方にしています&一般的にリアルタイムと呼ばれるものはイベント駆動かなと
*3:と言いつつも最近はこのやり方も浸透してきたので知っていればカジュアルに手を付けて良い手段ではあります.
*4:この領域は外部システムや受け渡しするデータの仕様を吸収する役割もあったりするのでただでさえ開発がきついので, 作るのは最小限に収めるのが良いと思っています.
*5:個人的にはフェデレーションはそれなりにリスクがある(元データソースのリソースに対して負荷をかけてしまうなど)ので, できるだけ避けるようにしています, 似たような事をしてシステムを落とした辛い過去が(小声).
*6:余談ですが, Google Cloud的には今の推奨はVertex AIとのこと.