日本で言えば同じ学年のレジェンド, アルバート・プホルスが通算700号本塁打を打って驚いている人です.
ここ最近, (休んでいる間のリハビリがてら*1)PyCon JP 2022の準備および, 来年以降のMLBを楽しく見るために野球データ基盤(ちなみにメジャーリーグです)を作っていたのですが, それがいい感じに完成しました.
- アプリとデータ基盤をどのように作ったのか
- どのような処理, どのようなユースケースで動かしているのか
- これらをどのようなアーキテクチャで実現したのか
以上の内容をこのエントリーに書き残したいと思います.
なおこのエントリーは,
PyCon JP 2022のトーク「Python使いのためのスポーツデータ解析のきほん - PySparkとメジャーリーグデータを添えて(2022/10/15 16:00-16:30)」の予告編でもあります.
なので, 後日のトークをお楽しみに(&他のトークと比べつつ, 行くかどうか悩んでいる方の指針になると幸いです*2).
おしながき
作ったもの
可視化・分析のためのダッシュボードを作りました.
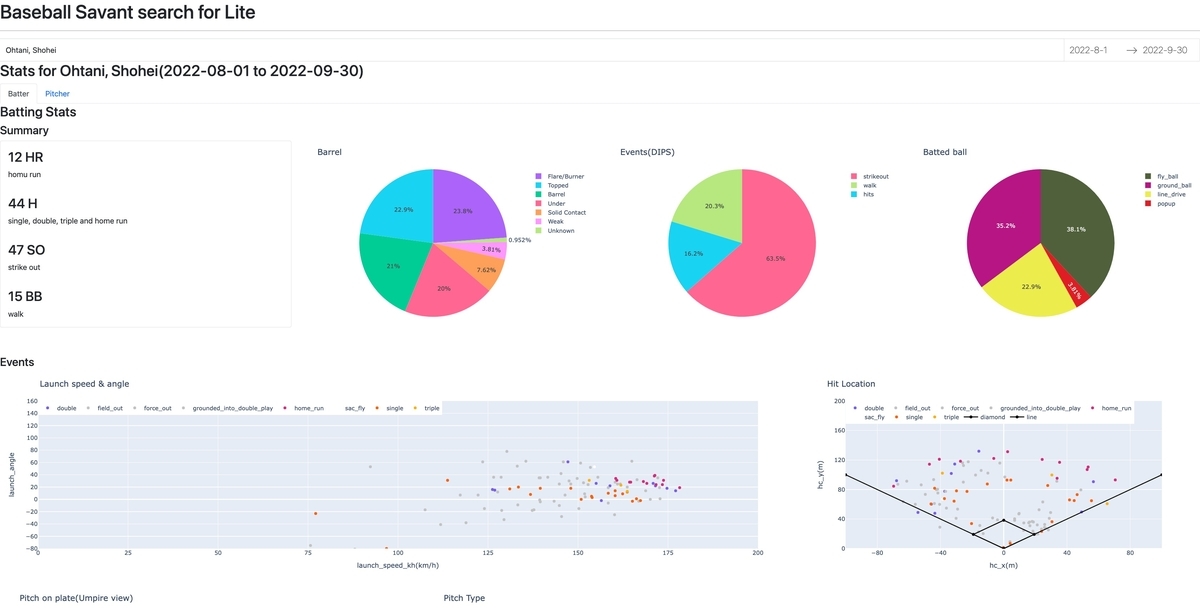
選手の名前と期間を入れると, 投打のデータを眺めることができるようになっています.
ダッシュボードは私個人の専用アプリと位置づけしていますが, PyCon JPで話している間(2022/10/15 16:00-16:30)に限り, 公開する予定です!
なおこのアプリケーションは,
- DashというPythonの(自称)ローコード(Low Code)*3なダッシュボード構築Frameworkで本体(画面と遷移)を構築, JavaScriptとHTMLは一切実装せず*4.
- グラフはPlotlyを使って描画.
- ホスティングはCloud Run, 認証認可は今の所Basic認証(Dashのモジュールで実装)*5.
そんな構成でできています.
全体像
このダッシュボードで野球のデータを出すまでにどういうアーキテクチャで実現しているかという全体像です.
ひと言で言うと, 全てGoogle Cloud上, ほぼ全てサーバレスなサービスで構築しています!
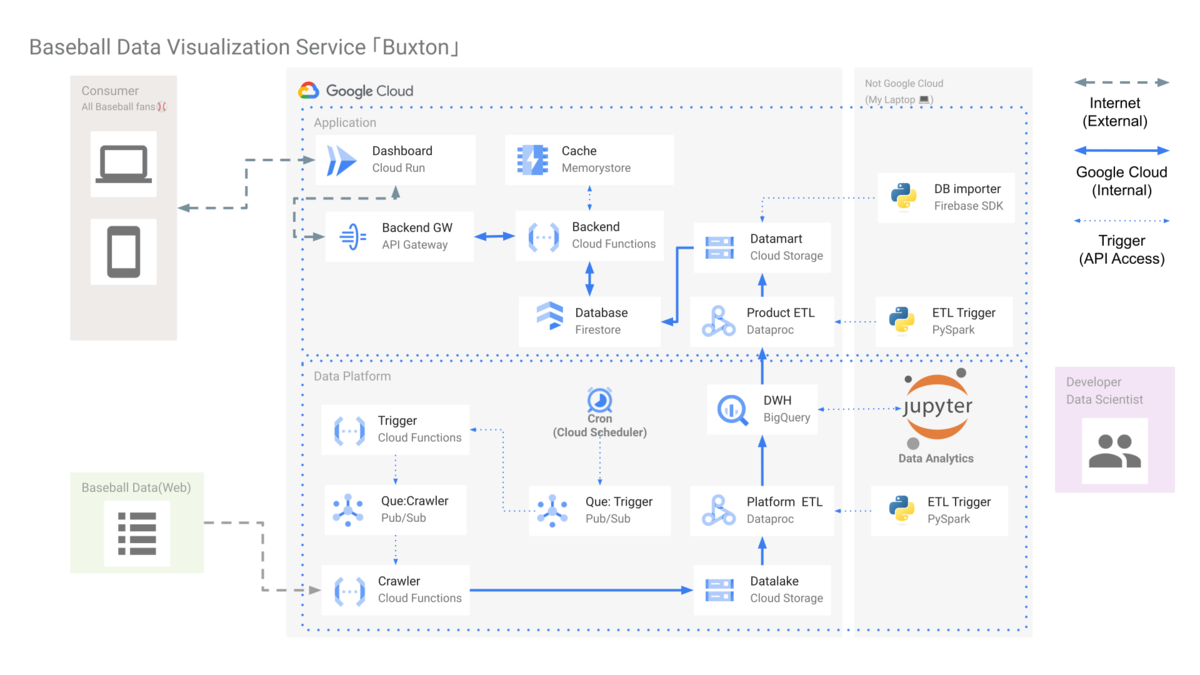
一見するとたくさんサービス・アプリがあって面倒くさそう&コストも掛かりそうですが, ほぼサーバレスなので月数10ドル程度で運用可能です.
アーキテクチャの特徴
とにかくサーバレスに拘りました.
GCEでVMを立てたり, GKEクラスタを立ててそこでアプリを運用してもいいのですが, VMを専有(≒使っていない間も待機)することで余計なコスト・無駄遣いが発生するのが嫌だったのと, そもそも個人利用レベルなら「使ってる時間だけ動けばいい」ので全サーバレスに振り切りました. 仕様の制約上サーバレスにできないものを除き.
利用している主要なサービスですが,
- Cloud Run(Dashのアプリケーションのホスティング)
- Cloud Functions(データのクローラー, ダッシュボードアプリのバックエンド他, 関数ベースの処理)
- Firestore(No SQL, ダッシュボードアプリに出すデータを保存するためのプロダクトDBとして利用)
- BigQuery(DWHとして利用)
- GCS(raw dataの保存先 & Dataprocのスクリプト保存)
- Dataproc(データを加工・変換して投入するETLとして)
- API Gateway(API Key認証にしたい意図があり, DashのアプリとCloud Functionsバックエンドの間に挟む形で利用)
これらのサービスを使っています(&細かいものを含めるともっとたくさんあります).
ユースケース
このダッシュボード・サービスの主要なユースケースは3つあります.
- ダッシュボード本体
- クローラーで収集したデータをDWH(BigQuery)に保存
- DWHデータをプロダクトのDatabase(Firestore)に保存
システム構成との関係性はこんな感じです.
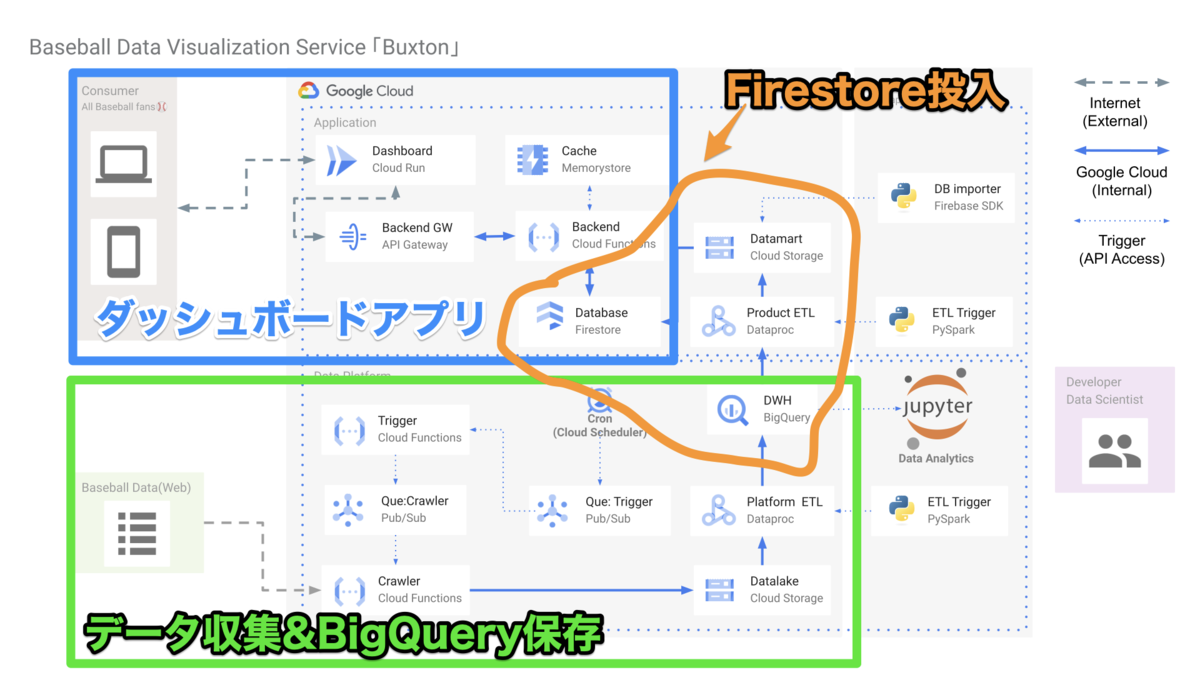
軽く解説します.
ダッシュボード
最終的なアプリケーションはこのような形で動いています.
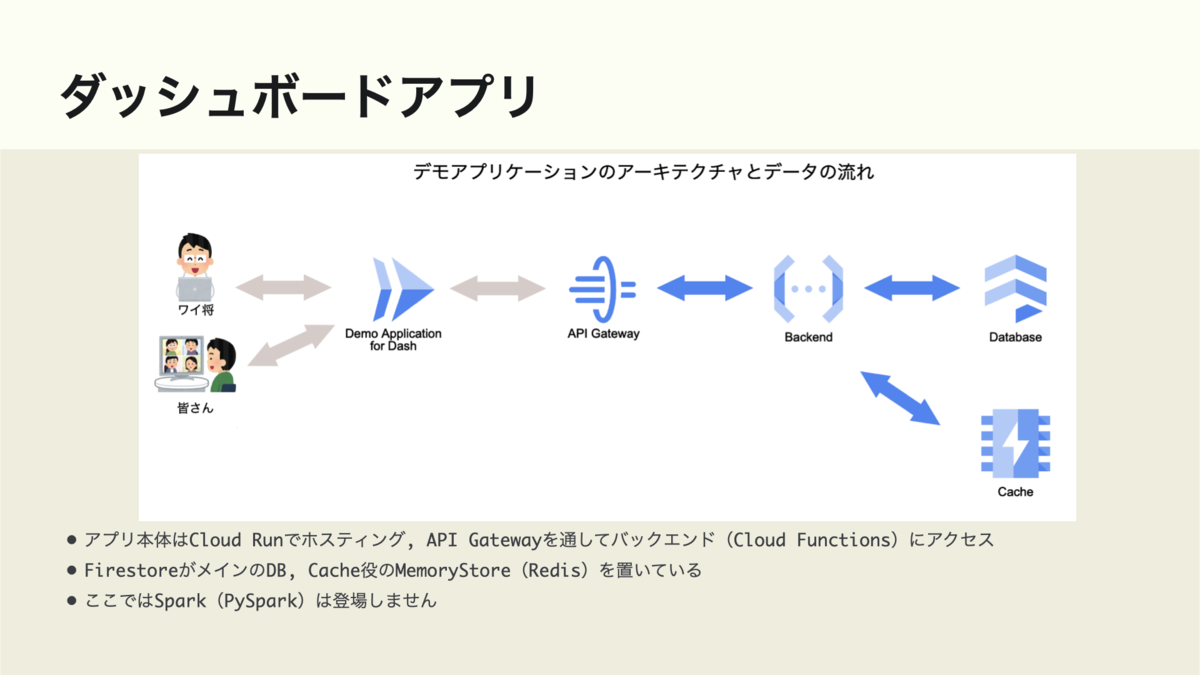
- Cloud Runでホスト
- Cloud Functionsにバックエンド(RESTful API)が存在. ちなみにこれはPythonのFunctions Framework*6で実装.
- DatabaseはFirestore, キャッシュするのにMemory Store上にRedisホストを構築
- 認証認可は敢えてAPI Gatewayを使ったAPI Key認証*7
データ基盤
データ基盤は基本BigQuery製のDWHとGCS上のRaw Dataがメインで, これらのデータをいい感じにする周囲の仕組みをDataproc, Cloud Functionsで構築・運用しています.
クローラーからDWH
クローラーをPythonで実装, Cloud FunctionsとCloud Schedulerで定期実行, 出来上がったCSVデータを集計・加工してBigQueryに保存.
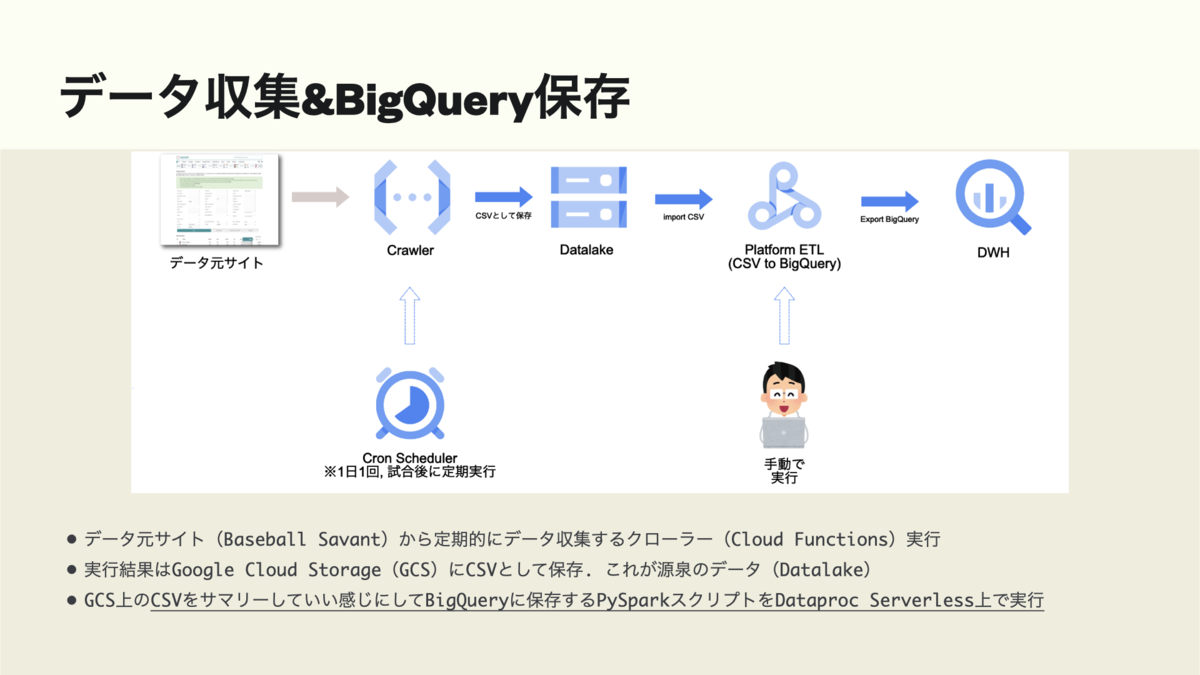
- Cloud Functions上にPythonでクローラーを実装. ちなみにコードはrequests-htmlとfunctions-frameworkを使ってます.
- 定期実行するためにCloud Schedulerを使ってバッチ処理を実現. Cloud Functionsとの接続はPub/Subを使用(Google Cloudでよくあるパターン).
- PySparkでデータ処理コードを実装, Dataproc Serverlessを手動実行してBigQueryにデータを保存.
詳しくはPyCon JP 2022で話します.
DWHからダッシュボードアプリ
BigQueryのデータを一度プロダクトDB用のRaw Data(JSONファイル)に保存し, Firestoreに投入.
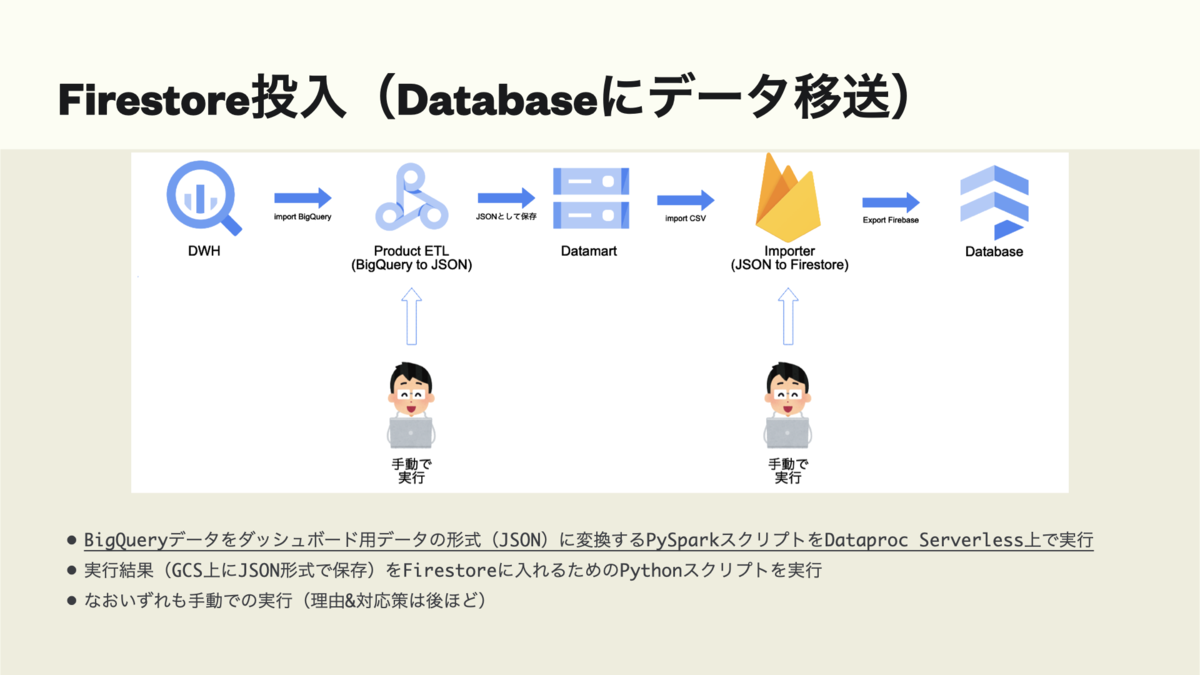
- BigQueryからJSONファイルを吐き出すまでをPySpark + Dataproc Serverlessで実行.
- 吐き出したJSONをFirebase SDKで実装した投入用スクリプトでFIrestoreに保存.
詳しくはPyCon JP 2022で話します(大切なので2度いいました).
今後の課題
言い換えると, 「ちゃんと運用する前に作りたい・整理したい」もの.
発表用に敢えてDataproc, FirestoreそしてMemoryStoreなどのサービスでオーバーエンジニアリング的に作り込んだもの*8を捨てつつ, 必要なものを揃えたい.
- プロダクトDB(Firestore)に関連する仕組み(MemoryStoreのRedis*9含む)はPyCon JP発表用に試験的に作ったもので実際はいらない(BigQueryに直接アクセスしてOK)ので整理が必要.
- Dataproc採用部分も同様にPyCon JP発表用に作ったので, これもCloud Functionsなどで作り変え. データ量的にCloud FunctionsやCloud Runの処理能力で対応可能なため.
- gcloud CLIなどを頼りに環境作ってる部分のIaC化. 具体的にはterraformなどでまるっと綺麗に作りたい.
- CI/CDの導入率は100%ではない, Cloud Functions のGitHub Actionsが公式に第2世代対応してないので, 対応次第整理したい.
- Datalake / Datamartの設計はエイやっとやったのでそのうち問題が起きるかもしれない.
結び&予告: PyCon JP 2022でトークします
最初に書いたとおり,
PyCon JP 2022のトーク「Python使いのためのスポーツデータ解析のきほん - PySparkとメジャーリーグデータを添えて(2022/10/15 16:00-16:30)」の予告編として書きました, 興味湧いた方はぜひ来てね!
というのと, この記事をお読みの方で,
- Google Cloudよく使ってる
- Pythonのデータ処理に自信ニキ
- データ基盤・活用なら俺にひと言言わせろ!!!
的な有識者・ツワモノの方々のご意見・ご感想・コメントをお待ちしております🙏
必要なら, PyCon JPの発表資料をDMします(秘密厳守で)
最後までお読み頂きありがとうございました&PyCon JP 2022で会いましょう!
Appendix - 参考資料
この辺のものを参考にしました.
書籍


作ってる途中に書いた過去記事
野球データの説明(過去記事)
*1:ポッドキャストあたりで話しますが, もうじき復活します💪
*2:PyCon JPに行く行かない, の判断はもちろん, 事前に内容を知っておくことにより, 「生で聞くか否かの判断」「他のトークを優先したほうがいいだろう」的な所の指針になればと思っています, 事前に知ることにより期待値と違った, 的なミスマッチングを防ぎたいお気持ちがあります(のでこのような形で先出ししました).
*3:初めて使いました&良かったので別のエントリーで紹介したいのですが, Low Codeかどうかは若干怪しいです, 割とガッツリ開発したような?
*4:DashのフロントエンドコンポーネントがReactでできておりかつ, Pythonの方で書いて制御ができるので一切JSとHTMLは書きませんでした.
*5:本音で言えばGoogle Cloudの機能をいい感じに使ってSSOしたいのですが, 発表中の一般公開とかあるので今は敢えて組み込んでいません, SSOの方法もまだ決めてないのもありますが.
*6:GoogleがCloud Functions, Cloud RunなどのKNativeベースで動くアプリをいい感じに実装するためにOSSとして公開しているFrameworkで, http(s)に限らず, 色んなプロトコル・インターフェースを持ったアプリをいい感じに実装できる仕組みとなっています. なお, 他のプログラミング言語版もあり&Python版はFlaskが下敷きとなって実装されています.
*7:単にCloud RunとCloud FunctionsをInternal接続でも良かったのですが, SaaS APIっぽく作りたかったのと, GCPのAPI Gatewayがどこまで使えるか試したかったので敢えてこういう構成にしました
*8:平たく言うとこの辺は発表用であり, 自分が遊びたかったので作っただけなのです. 仕事だったら絶対やらない構成だったりします.
*9:実は一番これにお金がかかっていて, 勿体ないので普段は止めています.