仕事はGoogle Cloudの取り扱い, 個人開発は野球のデータ分析基盤を作ることに一生懸命な人です.
最近はプロ野球もメジャーリーグも推しチームを観るのが辛いです*1.
趣味, いわゆる「個人開発」でやってる野球データサイエンスでSparkを楽して使うため, 久々にDataprocを使っているのですが,
- インスタンスを建てたり消したりするのに, Terraformを使ったが案外ハマった
- DataprocのJupyter Lab(もしくはJupyter notebook)上でBigQueryを使うのにもハマった
という事態に陥りました.
これは無事解決して「ああなるほど」と個人的には解決してメデタシメデタシ...なのですが,
- 業務なり個人の趣味なりでSparkを使う時にクラウドでサクッと使えるほうがいい(なぜなら自前で建てる・使うほうがもっと地獄だから)
- ...と, 私は思っているのですがそれに必要なノウハウって意外と言語化されていない(情報はあるけど探さないといけない)
- なんか, いい感じに解決できたので「全世界に公開するメモ」として残したい
と思い, このエントリーでそのハマったメモを残そうと思います.
TL;DR
- DataprocはTerraformで管理できます...が, 公式そのままのsampleは微妙なので注意.
- DataprocのJupyter Lab(Jupyter notebook)でBigQuery使えます.
おしながき
このエントリーについて
それなりにハイコンテクストな内容な為, 想定読者とアーキテクチャを先に紹介します.
想定読者
このエントリーは, エンジニアリング的な意味合いでは中級者向けの内容となります.
- Spark(PySpark)が何物か知っている.
- Terraformが何をするための物か理解している(使ったことがある・知っている).
- DataprocがGoogle CloudでSparkを使うためのサービスだと知っている.
以上を理解した上で(ご存知じゃない方はSpark, Terraform, Dataprocを理解した上で), 続きの話を読んでもらえると幸いです(≒これらの基本的な解説はしません.).
アーキテクチャ
このエントリーで想定しているアーキテクチャはこちらになります.
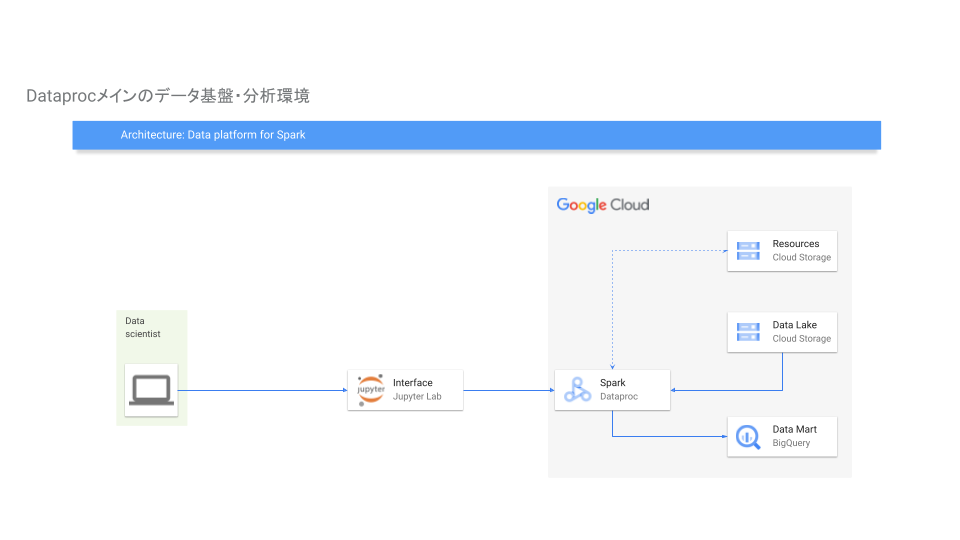
- Dataproc(Spark)のクラスタが存在していて, Jupyter Lab上で利用.
- Jupyter Labで使うnotebookはGCSに保存(上の絵でいうと「Resources」のBucketに保存)
- Sparkで使うデータは
- 元のデータソースはGCS Bucket(上の絵のData Lake)上にcsvファイルとして存在
- 最終的なデータソースはBigQueryに保存

このような構成を想定しています.
DataprocをTerraformで扱う
Google DataprocはTerraformで公式にサポートしています.
Terrfaform Registry: google_dataproc_cluster
ただ, 上記のExampleでは自分が想定しているアーキでは上手く行かなかったので以下のように書き換えて実行しました(以下, main.tfの設定).
resource "google_storage_bucket" "dataproc_bucket" { # Dataprocのファイルを保存するためのGCS Bucket name = "dataproc-bucket" location = "ASIA-NORTHEAST1" force_destroy = true } resource "google_dataproc_cluster" "dataproc_cluster" { # Dataproc本体の設定 provider = google-beta # Jupyter Labを使うためにbeta版を使う必要がある name = "dataproc-cluster" region = "asia-northeast1" graceful_decommission_timeout = "120s" labels = { name = "baseball-savant-cluster" } cluster_config { staging_bucket = "dataproc-bucket" master_config { num_instances = 1 machine_type = "e2-standard-4" } # workerの数とタイプをここで指定 worker_config { num_instances = 2 machine_type = "e2-standard-4" } preemptible_worker_config { num_instances = 0 } # Jupyter Labを使うための設定 software_config { image_version = "2.0-debian10" override_properties = { "dataproc:dataproc.allow.zero.workers" = "true" } optional_components = ["JUPYTER"] } endpoint_config { enable_http_port_access = "true" } gce_cluster_config { tags = ["name", "dataproc-cluster"] } initialization_action { script = "gs://dataproc-initialization-actions/stackdriver/stackdriver.sh" timeout_sec = 500 } } }
設定のポイントですが,
- providerをgoogle-betaに設定. これをやらないと, JupyterのComponentを有効化できない.
machine_typeを使いたいタイプに変更- あとはBucketの名前とか変更
これで良い感じに動きました.
自分の使い方的には, 「必要な時だけDataprocのインスタンスを立ち上げて動かし, 終わったらインスタンスごと消す」なので,
- 使いたい時に
terraform applyを実行してインスタンス構築 - 終わったら(お金がかからないように)
terraform destloy
これで手元のterraformでいい感じに管理できるようになりました.
Dataproc上のJupyter LabでBigQueryを使う
terraformを使ってDataprocをいい感じに使えるようになったので, 今度はDataprocのJupyter LabでBigQueryを使えるようにしてみました.
昨年, PySparkのスクリプトとして使えるようにしたものはありますが, Jupyterでも使いたいと思い, 調べて使えるようにしました.
DataprocのRepositoryに上記のサンプルコードがあり, これを真似することで上手く使えるようになりました.
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName('baseball_savant')\ .config('spark.jars', 'gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar') \ .config('spark.sql.debug.maxToStringFields', 2000) \ .getOrCreate()
.config('spark.jars', 'gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar') の部分がポイントで, ここで最新のSpark用のコネクタ(spark-bigquery-connector)を指定することで動くようになりました.
ここに記載されているspark-bigquery-connectorのバージョンを指定することにより動くようになります.
これでBigQueryへの読み込みも書き込みもいい感じにできました.
結び
というわけで,
- TerraformでDataprocを管理する方法
- DataprocのJupyterでBigQueryを使う方法
をまとめました, 調査して試行錯誤して若干ハマったのでまとめたメモとして残しました.
真にやりたいこととしては,
- このエントリーでやっている, 「メジャーリーグのトラッキングデータ」をSparkとBigQueryで使いやすい形にする
- 使いやすくした後に, メジャーリーグの成績予測をいい感じにするためのモデルを作る
- これらをSparkなり他のエコシステムでいい感じにする
なので, 引き続きこの仕組みを作っていきたいと思っています.
あと, せっかくTerraformを覚えたので過去に作ったものもIaC化していいようにしたいな...とか.
引き続きこの辺頑張っていきたいと思います, 最後までお読みいただきありがとうございました.
*1:贔屓チームは日本ハムファイターズとオークランド・アスレチックスですが, このエントリーを書いた6/26は奇跡的に両チームともに勝ちました笑