最近の野球界隈の出来事が斜め上すぎて驚いてるマンです.*1
本業の仕事および, 本業じゃない個人開発や趣味プログラミングにおいて,
- データの量が多くて
- 単位やフォーマットが不揃いで
- それでも仕事(もしくは趣味の分析)をこなすため, いい感じの使いやすいデータセットにしないと(使命感)
という機会は非常に多いです.
いや, 機会が多いというより多かれ少なかれ毎日戦っている気がします.
今回は, ちょっとした分析とお遊びのため, メジャーリーグの公式データサイト「Baseball Savant」のデータを使ったBigQueryデータベースを作りたくなったので,
- クローラーでBaseball Savantのデータを取ってCSVにして
- CSVからデータを集計したり整えたりしていい感じの単位にして
- BigQueryから使えるようにしてみたよ!
というタスクをGoogle Cloud Platform(以下GCP)の以下のサービスをつかってやってみたので紹介します.
TL;DR
- ちょっとしたデータの取得〜集計〜保存, 的なワークフローはDataproc(PySpark)でシュッとできちゃうぞ
- クローラーを動かす環境としてのCloud Functions(GCF)は使いやすい
- DataprocもGCFも, 仕組みを理解した上で使うとコードもシンプルに書ける
おしながき
このエントリーの想定読者
- Sparkとかで分散処理したいマン
- 仕事などで大量のデータを効率よく処理して何かをする必要が出てきたマン
- データ基盤やデータ処理のワークフローでGCPやDataprocを使っている・使おうと思っているマン
データサイエンティストというより, データエンジニア向けのエントリーとなります🙇🏻*2
Baseball Savant #とは
本題に入る前に, このエントリーで使ったデータ「Baseball Savant」を33.4秒くらいで紹介します.
Baseball Savantはひと言でいうと,
野球の試合のボールの動きおよび, その時の状況を記録したトラッキングデータ
です. メジャーリーグ全球団の本拠地に設置している「スタットキャスト*3」というシステムから得られるデータで,
- 投球データ(球速・リリース位置・球種・結果など)
- 打球データ(打球速度・角度・着弾位置など)
- 試合の状況データ(誰がどこを守っている, シフトを敷いてるかどうか, 得点・ボールカウントなど)
といった情報がぎっしり入っています.
最近はよく, 「オオタニサンのホームランの打球速度は180km/h!」みたいなニュースが流れると思いますが, それらのデータ元はここから生まれています.
なお, データを取得していい感じに処理するとこんな感じで描画ができます.
今回は上記グラフの元になったデータを抽出するまでの話となります.
(本当はもっと別のことをやるための準備もあるのだけどそれは後半にて)
実際やってみた
データそのものはRやPythonで既に取得用のライブラリがあったりします...が,
- Rは今回自分がやりたいタスクとちょっと合わない
- Pythonだと, pybaseballというライブラリでpandas DataFrameにできそうだが,色々余計なものも入りそうだしなんだか微妙
ということで,
- Baseball SavantをクロールしてCSVに保存するタスクをCloud Functionsで実装&運用
- 保存したCSVを集計してBigQueryに保存するタスクをPySparkで実装してDataprocで稼働
というアプローチでやってみることにしました&先に結論言っちゃうとこの方法でいい感じにできました👍
ここまでのアーキテクチャを絵にするとこんな感じです.
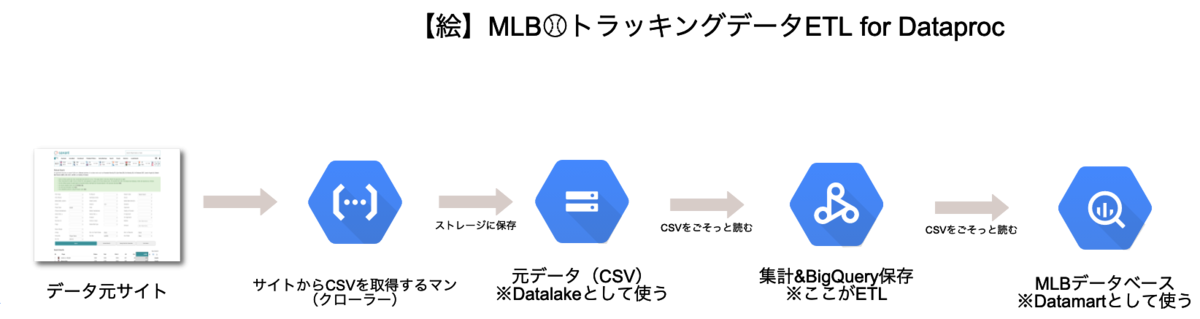
GCFでのクローリング
Baseball Savantには, 「フォームに必要な条件を入れて検索するとCSVがゲットできる」導線があります.
Statcast Search | baseballsavant.com
これを日々取得するような自動化をするため,
- Pythonでクローラーを実装
- ↑のクローラーをGCFで動かす
という作戦で行きました.
この辺は過去のブログで紹介した方法を踏襲しました.
GCFのコード(main.py)はこんな感じです.
from datetime import datetime, timedelta import base64 import pandas as pd from savant import query, PlayerType from gcp.storage import Storage storage = Storage() def extract(player_type: PlayerType, game_dt: datetime): """ crawl & upload :param player_type: Player Type :param game_dt: Game Day """ df = pd.read_csv(query(player_type, game_dt, game_dt)) storage.upload_from_string( path=f'statcast/{game_dt.strftime("%Y-%m-%d")}', filename=f'{player_type.value}.csv', text=df.to_csv(index=False) ) def mlb_statcast_exporter(event, context): """ Cloud Pub/Sub entrypoint :param event: pub/sub event :param context: pub/sub context """ if 'data' in event: game_dt = base64.b64decode(event['data']).decode('utf-8') game_dt = datetime.strptime(game_dt, '%Y-%m-%d') else: game_dt = datetime.now() game_dt = game_dt - timedelta(days=1) run(game_dt)
肝心のBaseball Savantからの取得(上記コードのsavantモジュール)はこんなノリです.
from datetime import datetime from enum import Enum BASE_URL = 'https://baseballsavant.mlb.com/statcast_search/csv' PARAMETERS = 'all=true&hfPT=&hfAB=&hfGT=R%7C&hfPR=&hfZ=&stadium=&hfBBL=&hfNewZones=&hfPull=&hfC=&hfSit=&hfOuts=&opponent=&pitcher_throws=&batter_stands=&hfSA=&hfInfield=&team=&position=&hfOutfield=&hfRO=&home_road=&hfFlag=&hfBBT=&metric_1=&hfInn=&min_pitches=0&min_results=0&group_by=name&sort_col=pitches&player_event_sort=api_p_release_speed&sort_order=desc&min_pas=0&type=details&' QUERY_FORMAT = 'player_type={player_type}&game_date_gt={game_date_gt}&game_date_lt={game_date_lt}&hfSea={season}%7C' GAME_DT_FORMAT = '%Y-%m-%d' class PlayerType(Enum): PITCHER = 'pitcher' BATTER = 'batter' def query(player_type: PlayerType, game_date_gt: datetime, game_date_lt: datetime) -> str: """ Statcast URL :param player_type: Player Type :param game_date_gt: Game Date Gt :param game_date_lt: Game Date Lt :return: query string """ params = QUERY_FORMAT.format( player_type=player_type.value, game_date_gt=game_date_gt.strftime(GAME_DT_FORMAT), game_date_lt=game_date_lt.strftime(GAME_DT_FORMAT), season=game_date_gt.year ) return f"{BASE_URL}?{PARAMETERS}&{params}"
あとはこれをPub/Sub経由で動かせば, こんな感じで日毎にCSVデータが取れるようになります.
DataprocのPySparkタスク
CSVデータとしてGoogle Cloud Storageにある状態ができたので, あとはよしなにBigQueryに入れればひとまず優勝できそうです.
いつもだったらこれもGCF上のタスクでやったりしちゃうのですが,
- 日別にファイルを作ってるので数が多い
- データを以下の単位に集計してまとめたい
- 生の投球・打球データ
- 選手マスタ(投手および打者にしか名前がない&各ポジションはID値のみ)
- シーズン年ごとにBigQueryのパーティション分割をしたい
と, まあまあやることが多かったので,
- 大量のファイルをまとめて面倒みるのに最適な分散フレームワークでいい感じに書けそう
- 分散フレームワークといえばSparkじゃん
- そうだ, この際だからDataproc使ってみよう!
...ということで, Dataprocに目をつけました.
やることはこんな感じです.
- GCSからBigQueryにデータを入れる(集計する)ためのworkflowなコードをPython(pyspark)で実装.
- 一時的にDataprocのクラスタを作成
- 上記コードをクラスタで実行, 終わったらクラスタを削除
これらを数100行程度のPythonコードと数行のgcloudコマンドでいい感じにやりました.
コード
workflowに当たるコードはこんな感じです.
- Spark DataFrameのスキーマを定義
- CSVファイルを読み込んでBigQueryに放り込む関数をいくつか実装
- 集計したい単位でSpark SQLでまとめて処理実行
これをdataproc_workflow.pyという名前で保存.
from datetime import datetime, timedelta from pyspark.context import SparkContext from pyspark.sql import SparkSession from pyspark.sql import DataFrame as SparkDataFrame from pyspark.sql.utils import AnalysisException from pyspark.sql.types import StructType, StructField, DoubleType, DateType, StringType, LongType # appNameは適当でOK sc = SparkContext(appName='savant_to_dataset') # デフォルトのフィールド数(25)では足りないので拡張 spark = SparkSession(sc).builder.master('yarn').config('spark.sql.debug.maxToStringFields', 2000).getOrCreate() # BigQuery保存時に使う一時的なGCS Bucket(Dataproc特有の設定) spark.conf.set('temporaryGcsBucket', '適当なGCS Bucket') # CSVを保存場所 GCS_ROOT = 'gs://保存したバケットの名前/statcast' # 日付フォーマット DATE_FORMAT = '%Y-%m-%d' # Spark DataFrame schema_b = StructType( [ StructField("pitch_type", StringType(), False), StructField("game_date", DateType(), False), StructField("game_type", StringType(), False), StructField("game_year", LongType(), False), # めっちゃ長いので省略 StructField("of_fielding_alignment", StringType(), False), StructField("spin_axis", DoubleType(), False), StructField("delta_home_win_exp", DoubleType(), False), StructField("delta_run_exp", DoubleType(), False) ] ) # CSVをSpark DataFrameにする関数 def read_csv(date: str, filename: str, schema: StructType = None) -> SparkDataFrame: try: return spark.read.format('csv').options(header="true", inferSchema="true").load(f'{GCS_ROOT}/{date}/{filename}', schema=schema) except AnalysisException: return None # 日毎のSpark DataFrameをひたすらUnion ALLでつないで一つのSpark DataFrameにする関数 def get_dataframe(start: datetime, end: datetime, filename: str, schema: StructType = None) -> SparkDataFrame: sdf = None while True: if (start.year, start.month, start.day) == (end.year, end.month, end.day): break dir_name = start.strftime('%Y-%m-%d') if sdf: _sdf = read_csv(dir_name, filename, schema) if _sdf: sdf = sdf.unionAll(_sdf) else: sdf = read_csv(dir_name, filename, schema) start = start + timedelta(days=1) return sdf # BigQueryに保存 def save_bigquery(sdf: SparkDataFrame, table_name: str): sdf.write\ .mode('overwrite') \ .format('bigquery') \ .option('table', f'baseball_savant.{table_name}') \ .option('createDisposition', 'CREATE_NEVER') \ .save() # 投手と打者それぞれで取得 start = datetime(2021, 4, 1) end = datetime.now() # それぞれのDataFrame sdf_batter = get_dataframe(start, end, 'batter.csv', schema=schema_b) sdf_pitcher = get_dataframe(start, end, 'pitcher.csv') # Temporary table sdf_batter.createOrReplaceTempView('batterCsv') sdf_pitcher.createOrReplaceTempView('pitcherCSV') # Spark DataFrameから必要なデータを取るためのSpark SQL query = ''' select pitch_type, game_date, game_type, game_year, # これもめっちゃ長いので省略 of_fielding_alignment, spin_axis, delta_home_win_exp, delta_run_exp from batterCsv order by game_date, game_pk, inning, inning_topbot desc, at_bat_number, pitch_number ''' # トラッキングデータをBigQueryに sdf_tracking_data = spark.sql(query) sdf_tracking_data.createOrReplaceTempView('trackingDataset') save_bigquery(sdf_tracking_data, 'tracking') # 選手リストをSpark SQLで抽出して作成 sdf_player_b = spark.sql('select distinct game_year, batter as player_id, player_name from batterCsv') sdf_player_p = spark.sql('select distinct game_year, pitcher as player_id, player_name from pitcherCSV') sdf_player = sdf_player_b.unionAll(sdf_player_p) sdf_player.createOrReplaceTempView('playerDataset') sdf_player = spark.sql('select distinct game_year, player_id, player_name from playerDataset') sdf_player.createOrReplaceTempView('playerDataset') sdf_player = sdf_player.withColumn("game_year", sdf_player["game_year"].cast(LongType())) save_bigquery(sdf_player, 'player')
なお, 最初はローカル(作業用のMacbook Pro)に立てたSparkクラスタでデバッグしてからやろうと思ったのですが,
- Dataproc特有の拡張でGCSやBigQueryと楽に繋げられる
- ↑をローカルで再現するのは微妙というか無理
- デバッグ中だけクラスタを立ててやればいいのでローカルの環境はいらない
という結論に至りました.*4
実際に動かしてみる
あとは動かせばおしまいです.
これらはgcloudコマンドで完結しちゃいます.
cluster-baseball-savant という名前でDataprocにSparkクラスタを作って実行します.
クラスタを立てる
$ gcloud dataproc clusters create cluster-baseball-savant --enable-component-gateway --region asia-northeast1 --zone asia-northeast1-a --master-machine-type n1-standard-4 --master-boot-disk-size 500 --num-workers 2 --worker-machine-type n1-standard-4 --worker-boot-disk-size 500 --image-version 2.0-debian10 --optional-components JUPYTER --project {ご自身のプロジェクト名}
オプションでjupyterをつけたのでJupyterからも動かせます(が今回の例では使わない).
動かす
dataproc_workflow.py を作成したクラスタで実行.
コードは勝手に転送&実行されます.
状況はコンソールログもしくはGCPコンソールで確認できます.
$ gcloud dataproc jobs submit pyspark dataproc_workflow.py \
--cluster=cluster-baseball-savant \
--region=asia-northeast1 \
--jars=gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar
ポイントとしては, BigQueryを使う際はオプションでjarを足す必要があります.
--jars=gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar
クラスタを閉じる
処理が無事に終わったらクラスタを削除
$ gcloud dataproc clusters delete cluster-baseball-savant --region=asia-northeast1
これを忘れると放っておいてもお金がかかるので忘れずに絶対やりましょう.
結び
今回はDataprocで目的のデータを得ることができました.
なお, かかった費用をざっくりいうと,
- GCFはゼロ円(無料枠範囲)
- Dataprocは裏側で動いているCompute Engineのサーバー代が約$4(1日)
と, Dataprocを動かすお金が少々かかりました, 実行のたびにクラスタを作って消してもこの金額です, 個人開発的には少し贅沢な手段なのかも...
とはいえ時間を溶かすこと無く大量のデータをさばくのに最適とわかったので今後も積極的に使おうと思います.
なお, このネタには続きがありまして.
- 今回得たデータを元に, 打者オオタニサンの傾向を徹底分析
- 徹底分析した結果を機械学習でいい感じにして「オオタニサンが誰からホームランを打つか」を予測してみる
- 予測モデル作りのML基盤として引き続きSpark(Dataproc)を使っていく
ということで, PySpark第二弾ネタは近々あるかもしれません*5.
最後までお読みいただきありがとうございました.
参考文献
今回のプロダクト作成および検証に際し, 以下の書籍・資料を参考にしました.

![Google Cloudではじめる実践データエンジニアリング入門[業務で使えるデータ基盤構築]](https://m.media-amazon.com/images/I/51w8dXNHXbL._SL500_.jpg "Google Cloudではじめる実践データエンジニアリング入門[業務で使えるデータ基盤構築]")
*1:前回ブログからの一ヶ月で侍金メダル, オオタニサン40号ホームラン, 翔さんの色々, 杉谷ベース空過事件といろいろありすぎなのですがそれは
*2:スポーツデータとか野球データに興味あるマンが真似してもOKですが, それなりのエンジニアリング・スキルが要求されるのでやるかたは結構頑張る必要があるかもです
*3:今回紹介したトラッキングデータ以外にも, 映像データがあったりとかなり大掛かりなシステムだったりする
*4:開発環境もクラウド前提, クラウドファーストでいいのかもしれないと改めて思った事案でもありました. そのほうが開発早いってのもありますし.
*5:更にいうとこのブログのネタはPyCon JP 2021のCfPとして提出していたネタでもあり, 残念ながらこのネタは落ちた(別のCfPが採択された)事もあり, 供養ネタして法要のつもりで書きました笑