プログラミングとプロダクト作りは楽しいよ, っていう「個人開発ネタ」の話です.
スポーツ観戦, 具体的には野球のデータ分析DX(Digital transformation)*1を実現しました.
記事の前半はプロダクト企画とアーキテクチャ, 後半はDash(Python)を使ったマルチページ・データ・アプリケーション開発の話となります.
TL;DR
SpreadsheetとPythonのアプリケーションでいつでもメジャーリーガー(全選手)のパフォーマンスを好きな条件で可視化できるようにしたら野球が面白くなりました.
https://example.com/batter/ohtani-shohei/2024-03-20/2024-04-28?cache=false みたいなURLを開くと,
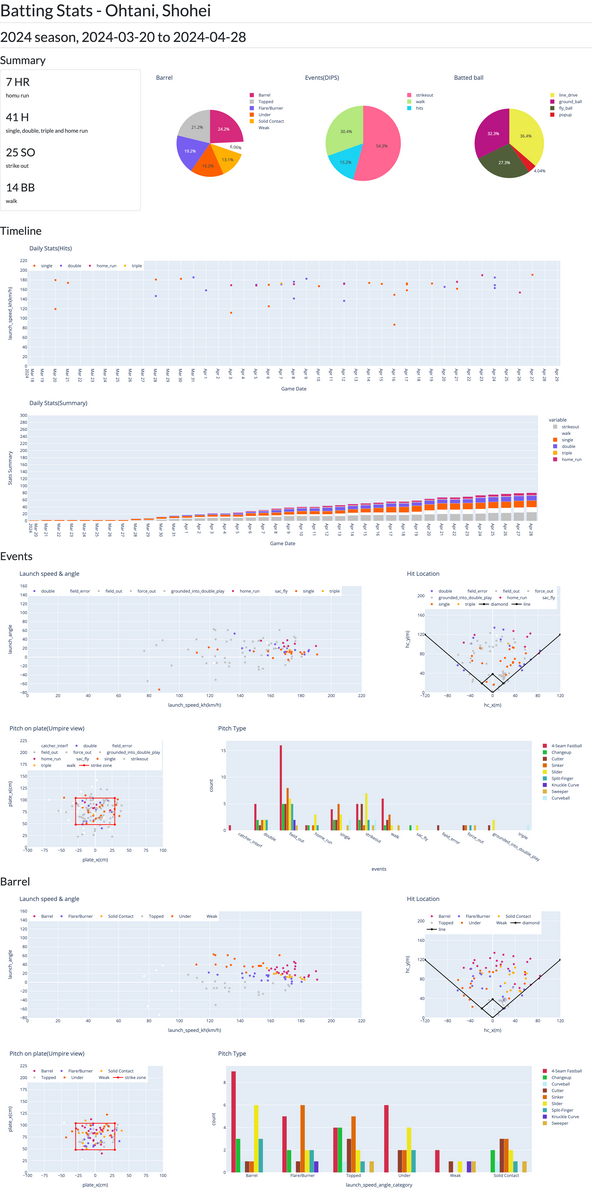
以下の成績をいい感じにグラフ・可視化するモノを作りました.
- 一般的に知られた成績*2
- 本塁打, 三振, 四球などの通常成績
- 毎日の成績(ヒットの本数と種類, 累計)
- 球種ごとの成績
- パフォーマンスがわかる数字*3
- 打球傾向(フライ・ライナー・凡打)
- 打球到達位置(フィールド上のどこに飛んだか)
- 打球の勢い(打球速度・角度・種類)
勘の良い方はお気づきかと思いますが, 「野球版Tableau」「野球専用Looker Studio」を実装*4した感じです.
これでオオタニサンの調子だろうが今永が好調な理由*5もとりあえず可視化して探ることができます, 一発で.
なお, 投手版もあります&これらを使った分析ネタは前回のブログで紹介しました.
これをプロダクトとしてどうやって企画し, 実装したか紹介します.
スポーツ観戦DX企画とアーキテクチャ
プロダクトなので企画はあります, そしてアーキテクチャも存在するのでちょこっと紹介します.
なぜ作ったのか
「めっちゃ野球が好きだから」「プログラミングがとにかく好きで」というのが雑な理由ではありますが(人はこれを「情熱」と呼ぶらしいです*6).
真面目な理由を書くと,
- PyCon JPやデブサミ, このブログといった「技術的なアウトプット」を代表するプロダクトが欲しい.
- MLBの情報サイト(公式・非公式)が自分にとって使いにくく, 「自分的に使い勝手が良い」「やる気を出したら拡張可能」なデータプラットフォームが欲しい.
以上が作った背景となります.
PyCon JPやデブサミ, このブログといった「技術的なアウトプット」を代表するプロダクトが欲しい.は本当そのままの理由です.
仕事的にやったことや作ってるものを公開しにくい状態*7である為, 「これは俺が作ったものだから俺が自由に発表する」モノが欲しかったのは事実*8です.
このブログのテーマ的にはもう一つの理由である
MLBの情報サイト(公式・非公式)が自分にとって使いにくく, 「自分的に使い勝手が良い」「やる気を出したら拡張可能」なデータプラットフォームが欲しい.
これが重要だったりします.
ワイ「MLBの情報サイトがとにかく使いにくくて自分の為の道具が欲しい!」
この心の叫びが最たる理由だったりします.
MLB情報サイトが使いにくい
2024年5月2日現在, 私達が使えるメジャーリーグの情報は以下のとおりです.
- インターネット放送を含めたTV媒体. 日本だと各テレビ局+ABEMA, MLBは公式チャンネル(MLB.TV)など.
- 一般的な情報提供をしているサイト. MLB公式(mlb.com), 各ニュースメディア(ESPN, スポナビなど).
- よりマニアックな情報を提供かつ, 一部データ取得ができるサイト. FANGRAPHS, BASEBALL REFERENCEそしてBaseball Savant.
TV媒体と一般情報サイトはともかく, 私はマニアックな情報から統計的・データサイエンス的に野球を追いかけたい人なのでよりマニアックな情報を提供かつ, 一部データ取得ができるサイト.が最も重要な情報源だったりします.
特にMLB公式の一部となっている「Baseball Savant.」は様々なデータがあるだけでなく, ダウンロードもできてしまうという夢のような情報源となっています.

これは野球好きな人なら一晩余裕で時間を溶かせるコンテンツなのですが問題が一つあります.
ワイ「Baseball Savant, Webサイトとしてめちゃくちゃ使いにくいのでは😇」
例えば必要なデータを探して取得・可視化するまで以下の検索画面と戦う必要があります.

これがとにかく使いにくいのと,
- 必要なデータやグラフにアクセスするまでの体験が微妙*9.
- 意味がわからないグラフ・ビジュアライゼーションが多い. というより検索*10含めて機能多すぎ*11.
- CSVデータを取得するまでの導線がわかりにくい.
上げればキリがない問題がいくつかあったため,
ワイ「自分好みのBaseball Savantを作れば優勝じゃん!」
こちらを思いつき, 2022年の夏から企画・開発を行い本年(2024年)にようやっとVer1.0と呼べそうなモノを実現しました.
この辺が途中の成果物だったりします.
行き着いたアイデア
一言で言うと, 「選手毎にユニークなURLを持ったデータダッシュボードを作ろう」という作戦に至りました.
約2年近く色々触ったり開発した結果, 現時点の完成版でのアイデア(というよりユースケース)はこちらに収まりました.

ユーザー(主に私)目線でざっくり書くと,
- 毎日更新されるデータをDashboardアプリ(ブラウザアプリ)で見る. ちなみにスマホ・タブレットも対応.
- データはDWH(BigQuery)に毎日保存される. なおデータ更新の仕組みはデータ基盤(SoR)として別に用意.
- 各選手の専用URLを毎日更新. 具体的にはSpreadsheetのコネクテッドシート機能を使い, URLを自動更新.
以上のアイデアに行き着きました.
全体アーキテクチャ
将来的な技術検証および, コスト圧縮を目指すためサーバレスアーキテクチャとマイクロサービス化を行いました.
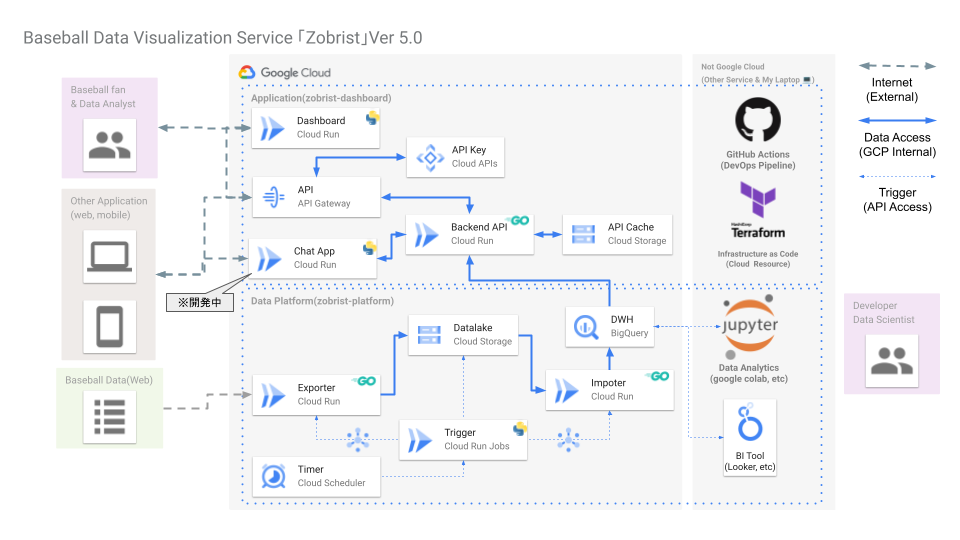
こだわりポイントは,
- 役割ごとのマイクロサービス化. データ可視化もデータ基盤も小さなアプリケーションとし, IFを明確に決めてマイクロサービス化. ただし凝ったことはやらない.
- 完全なサーバレスアーキテクチャ化. 「使っていない間はCPU/Memoryおよびサーバ・リソースは不要」なため, Cloud RunやCloud Functions*12, BigQueryといったサービスを利用.
- DevOpsワークフローに従ったCI/CD. 手動リリースは一部に留め, 主要なサービス・アプリケーションはすべてGit TriggerでCI/CDを回す.
以上となります, 正直仕組み作りに苦労(特にDevOps)しましたが, 作りきった結果として開発体験という名のDX(Developer's eXperience)も向上したのでとても良きという感じでした.
この辺の話は去年〜今年にかけていくつかのアウトプットにて公開しています.
この辺はまだまだ話せるネタが大量にあるので今後も発信するつもりです*13.
データ基盤(SoR)の構築
以上のプロダクト企画, アーキテクチャを下に最初に実現したのが,
Baseball Savantのデータを毎日BigQueryに溜め込むデータ基盤.
の構築と運用でした. 今どきのシステムにおける専門用語で言うところの「SoR(System Of Records)」というやつです.

Baseball Savantが毎日データ更新しているのは把握していたので,
- ダウンロードするCSVのパターンを調べて仕様化
- 手動更新などのPoCを重ねてBigQueryのスキーマを設計
- いくつかのプロトタイプを経てCloud Run + Cloud PubSubでデータ基盤化
しました.
この話はちょっと前のブログにも書いたので置いておきます(ここでは解説しません).
これで新鮮なデータを毎日仕入れる準備はできました.
あとはどうやって可視化するか?だけです.
データアプリ(SoI)
データ可視化はDash(Python)を使いました.
Plotlyという可視化ライブラリをFlaskベースのWebアプリケーションとして構築できるスグレモノです.
単に可視化するだけならTableauやLooker Studioを使えば良いのですが,
- 野球ならではの独特な可視化表現. 具体的には投手のストライクゾーンやフィールド(球場)表現など.
- Jupyterで実験的に可視化したコードを手間なくWebアプリケーションとして移植したかった.
以上の理由で自分でスクラッチする必要があると判断し, 自作しました.
SPAで検索ページ
初期プロトタイプは「選手名」などを入れたらグラフを出すSPAとして作りました.

- Dash側でグラフモジュールとアプリを実装
- BigQueryのデータはバックエンドAPI(Go)を介して取得
- 検索(選手名の入力など)の挙動をCallback eventとしてAPIを呼び出し, アプリにデータをマッピング
これでコツコツと作った*14結果, ひとまずBaseball Savant代わり(かつ自分で自由に作れる)ダッシュボードを手に入れました.
これができた時はすごく嬉しかったですね, 色々検索しまくった記憶があります.
ただ, この方式にはいくつか問題がありました.
- 検索するのが面倒くさい. 簡易的なサジェストも実装しているものの, 毎回検索は辛い.
- 選手や期間ごとにブックマークできない. 毎日チェックしたい選手(例えばオオタニサン)は決まってるのだからブックマークできるようにすべき(SPAで作っちゃったので毎回検索する必要があった).
この問題は約1年半放置していましたが, 2024年になって問題が顕著化*15(特にブックマークできない問題)したため, 解決方法を探り対処することにしました.
マルチページ化
結論から書くと, Dashでマルチページ(URLを静的・動的に定義)する方法が提供されていました.
Multi-Page Apps and URL Support | Dash for Python Documentation | Plotly
TypeScriptとかで作り直しを覚悟していた*16ので見つけた時は小躍りしましたw*17
上記のお作法に従い,
- 打者成績を
/batter/ohtani-shohei/2024-03-20/2024-04-28みたいなURLで表現する. - 投手成績は
/pitcher/ohtani-shohei/2024-03-20/2024-04-28で表現. - トップページは引き続き検索画面とする.
このようにアプリを再設計し, リファクタリングしました.
- app.py - pages |-- batter.py # 打者成績 |-- pitcher.py # 投手成績 |-- top.py
これでいけます.
app.py
メインのアプリケーションはこんな感じ.
import dash # type: ignore from component import META_TAGS, external_stylesheets from dash import Dash, html # type: ignore from dash_auth import BasicAuth # type: ignore from environment import BASIC_AUTH, FLASK_SECRET_KEY, TITLE # Base Application app = Dash(__name__, meta_tags=[META_TAGS], external_stylesheets=external_stylesheets, use_pages=True) # use_pagesオプションを有効化する. # Basic Authで認証(ここは別方法に変える予定) auth = BasicAuth(app, BASIC_AUTH) app.title = TITLE app.config.suppress_callback_exceptions = True app.server.secret_key = FLASK_SECRET_KEY server = app.server # 元となるアプリケーションのContainer(ここにelementを突き刺すことになる) app.layout = html.Div([dash.page_container]) if __name__ == "__main__": # Not used in production, only for development app.run_server(debug=True)
pages配下の各ページ
batter.pyとpitcher.pyはこんな雰囲気
import dash # type: ignore # URLを登録 dash.register_page(__name__, path_template=f"/batter/{URL_PATTERN}", title="Batting Stats") # 投手版だとこれ # dash.register_page(__name__, path_template=f"/pitcher/{URL_PATTERN}", title="Pitching Stats")
ちなみに全体像はこちらです.
Topページ(top.py)は登録するURLが変わるだけです.
# Register dash.register_page(__name__, path="/")
これでひとまずマルチページにできます.
SpreadsheetからURLを確認
選手および期間ごとのURLをBigQuery Viewで用意, コネクテッドシート機能で定期的に更新することで常に最新のメジャーリーガー成績(のURL)を取得するようにしました.
ユースケース的には下記の部分です.
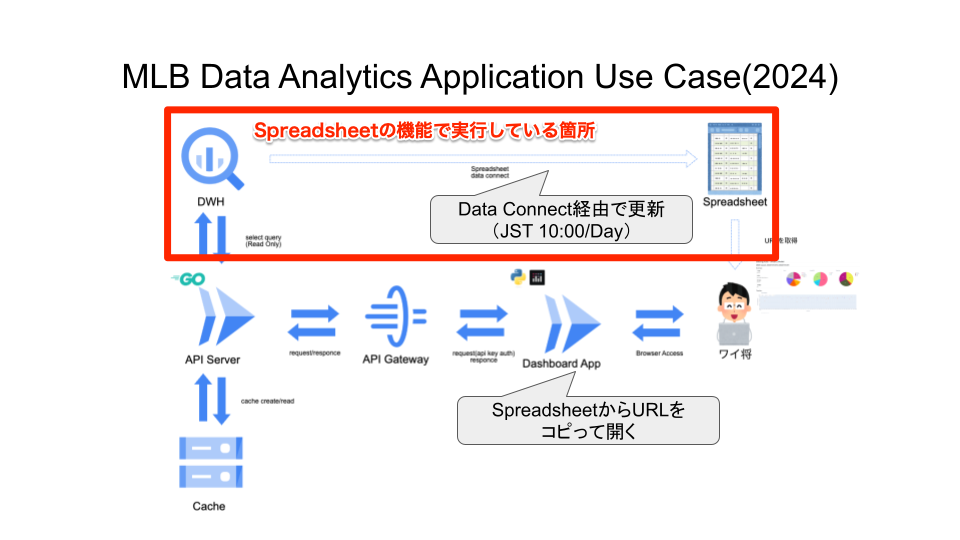
BigQueryにあるデータからURLの組み立てはできるので,
- BigQuery側でViewを用意
- Spreadsheetのコネクテッドシートで用意したBigQuery Viewを指定し, 定期的に更新するようにセット
- コネクテッドシート(実態はピボットテーブルした結果のシート)を参照し, URL一覧のシートを作成
これで作ってみたらいい感じにできました.

SpreadsheetからBigQueryを直接使えるのは本当に神機能*18だと思います, ありがとうGoogle CloudとGoogle Workspace.
これでスポーツ観戦, 特にメジャーリーグを見るときの「この選手はどんな選手なのか?」的なアドホックな分析がSpreadsheetから選手を探してリンクをクリックするだけでできるようになりましたとさ.
課題
自分の欲しいものができたのと, PyConJPなどのカンファレンスやこのブログのネタになるものもできて満足なのですが,
- 検索性がイマイチな問題
- 通知が欲しい
- クラウドの運用コストがほんの少しかかってる
という新たな課題も爆誕しました.
検索性がイマイチ
Spreadsheetから選手名を探してリンクを探すのがウザい
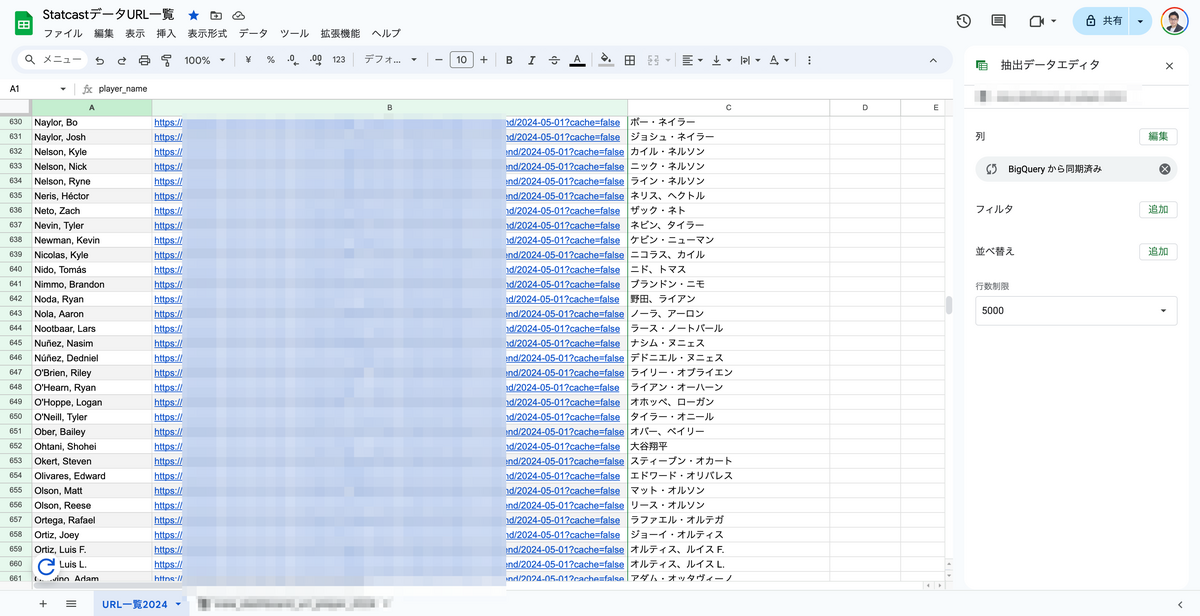
上記のSpreadsheetから選手を探すのですが, PCはいいとしてタブレットやスマホからは使いにくいんですよね(理由は言わずもがな).
ちなみに少しでも探しやすいように, Spreadsheet上で翻訳(GOOGLETRANSLATE関数)も試みましたがちょっと微妙でした*19.
今後はこのSpreadsheetを対話型のチャットアプリに変更する(チャットアプリを開発する)事で切り抜けようと考えています.
Streamlitで一旦作ってお試しかなと.
通知が無い
「あまり知られていないけど活躍している選手を通知する」みたいな機能が無い.
一言で言えば「今見るべき選手をリコメンドしてくれ*20」という所でしょうか.
これに関しては,
- 何かしらの指標でランキングを作って上位をSlackで通知する
- SPAのコンテンツを活躍している選手のランキングにする
- GeminiあたりのAIを駆使してリコメンドする何かを作る
このいずれかをやることで解決するのではと思っています.
コストの心配
データアプリおよびデータ基盤のランニングコストが昨年の倍以上になってしまった.
マルチページのレンダリング, データ基盤のワークフロー(バッチ処理)の変更で月額$20ちょいかかっています.
アプリいやプロダクト全体の規模を考えるとこれでもかなりお安い感じなのですが,
- Dashのページを静的コンテンツ*21に変更する(=Cloud Runなどのサーバ・Containerでのホストをやめる). 今は事実上SSRな作りなのでこれを改める.
- バッチ処理のスペック見直し. こちらはすぐにできそう.
などなど, コストを下げる処置を行うつもりです.
結び - プロダクト開発しようぜ.
「プログラミングとプロダクト作りは楽しいよ」というモチベーションと休日プログラミングが生んだ野球データ基盤とアプリケーションの話を長々と紹介させてもらいました.
技術検証的な意味合いも強いので結構ちゃんとした構成(ガチのプロフェッショナル向けの構成)で作っちゃいましたが,
- データ投入とバッチ処理をDjango(他のFW・言語でもいい)で作る
- Django REST FrameworkあたりでAPI化する
- ReactでもVueでも何でも, 好きなFW/ライブラリでアプリ化する
これでも十分には作れるので, 「自分も似たようなモノ欲しい!」なんて思った方は私の真似はせず知ってる手段でライトに作ってみることを推奨します.

最近はこういう本も出ているし真似もし易いのかなと*22.
最後に自分からのメッセージとして,
「事業会社のエンジニアになりたい」「SIerなりITコンサルなりのエンジニアになりたい」どっちでもいいけど自分でプロダクト作って学ぶのは色々手っ取り早くスキルと経験付くのでおすすめやで!
プログラミング学習をやる, 転職サイトのレジュメを充実化する(技術的なスコアを上げる), 最新の情報をキャッチアップする.
どれもエンジニア(とエンジニア志望の人)が好きで目指すことだし大事だと思うのですが...
もっと楽しく「モノ」を作ってプログラミングやエンジニアリングを楽しみませんか?*23
これが一番成長するコツだと思うのでちょっと気になる方はできることからやってみましょうよ.
...という私からの提案でこのエントリーはおしまいです, 最後までお読みいただきありがとうございました.
Appendix - 参考書籍・文献
このエントリーに関連するもしくは, 読んでおくと良い書籍を合わせて紹介します.
データ基盤・アプリ
このエントリーでやってることは「実践的データ基盤」の一つの回答のつもりだったりします.

最近出た本ですがこちらもデータ基盤的な意味でおすすめ.

Plotly関連はこちら

Google Cloud
書籍関連はこちらを参照.


このブログでも以前データ基盤向けのアーキの話などを乗せていますのでご参考までに.
DevOps
入門継続的デリバリーがすごく良かったです, いずれ別記事で紹介.

今回紹介しきれなかったデータ基盤のDevOpsは以前のエントリーを御覧ください.
*1:もうかれこれ10年以上手掛けてますがやっと完成形ができた感あります.
*2:Statcastのデータをサマリーして出しているため実際成績と微妙に異なる点もありますが知りたいのは雰囲気なので問題ではない.
*3:成績に裏付けされるトラッキングデータを元にした数字. 具体的には打球・投球の速度や座標, 角度など. ちゃんと計算したら3D表示したり変化球の曲がりなどを可視化可能(ですがまだそこまで実装していない).
*4:単にグラフにするだけならLooker Studio使う方が断然良いのですが, 野球のダイヤモンド(フィールド)を表現するなど自前で作るものがいくつかあったので自作しました.
*5:日本時間2024/5/2時点での理由としては「三振がめっちゃ取れてる割に本塁打打たれない, 四球ださない」という理由で無双しています, 流石に出来過ぎなのでいずれ飛びそうな気もしますが.
*6:実はこれがいちばん大事な理由な気もします, やる気出さないとここまで作れないので.
*7:会社の技術ブログを書く時に問題になるやつです. 面倒くさいので私は自分で作ったものをネタにしています.
*8:それで言うと前職以前含めて過去アウトプットは全部これに該当するのですがそれはさておき.
*9:高機能すぎて必要な情報にたどり付くのに手間な気がする.
*10:各データカラムでand検索ができるのは良いのですが, にしても多すぎなのでは!?
*11:グラフやビジュアライゼーションはキレイなのですが時折何の意味があるかわからない可視化があったりなど.
*12:2023年時点では使ってましたが今のバージョンではCloud Runに移行しました.
*13:今回はデータアプリ(Dash)の話題に触れているものの, バックエンドAPI(Go)などまだ掘っていない話題も大量にあります.
*14:開発を始めた2022年当時, PyConJP 2022での登壇が控えており, 「いい感じに発表で映えるアプリが欲しい!」という事情もあってコツコツかつ, 急ピッチで開発を進めました. 趣味アプリの割には結構デスマだった記憶が.
*15:2024年は多くのアジア出身選手(主に日韓)がメジャーに渡っており, 気になる選手を追いかけるのに選手ごとにURL作ってブクマしたくなるというISSUEができました. これが問題の顕著化.
*16:と言いつつ, いつかはDash for Pythonを捨ててすべてTypeScriptで作り直す未来は見えています.
*17:できるとは知らなかったので. やっぱりリサーチは大事です.
*18:最終的にSpreadsheetやExcelで何かをやるという機会は多いので本当に便利です, 機能の存在は知ってましたが今回初めて使ってちょっと感動した.
*19:笑える翻訳が会って面白かったですがw
*20:本当はこれが一番やりたいことです.
*21:ページ単位でやってることはグラフ単位でWidget化しても良いのではと考えています, やってること的に.
*22:とりあえず手を動かして一通り覚える目的では良い本だと思います.
*23:最近プログラミングが学問だの必須スキルだのとか色々言われてるせいか, 「モノづくり」「面白いことをやる」的なアート性が減ってる気がするんですよね. もっとそういうのを大切にしてほしい.