このエントリーを書いてる今日(9/29)と明日で有給消化期間が終わるマンです.
20日間, Banksy展を楽しんだ&新しいメガネを求めて新宿に行った以外, 地元の杉並区〜吉祥寺エリアからほぼ動きませんでした.
Stay Home的な意味合いもあるのですが, 10/16(土)にPyCon JP 2021でお話をする事もあり, その準備(と信長の野望*1)に多くの時間を割いていました.
PyCon JP 2021からトーク紹介 #pyconjp
— PyCon JP (@pyconjapan) 2021年9月14日
「実践Streamlit & Flask - AIプロジェクトのプロトタイピングから本番運用までをいい感じにするPythonicなやりかた」
Web programmingトラックのIntermediate向けトークです。
楽しみですね。チケットはconnpassで発売中!(固定ツイート参照ください)
スライドも発表内容もいい感じにまとまったのであとは練習と足りない所作って微調整って感じなのですが,
ブログおよびPyConの発表で「データサイエンティストとエンジニアがきれいに分かれる分水嶺なんて無いんやで」って言う話をしようと思い、雑にお絵描きした結果がこれだった
— Shinichi Nakagawa / 中川 伸一 / Senior Engineer (@shinyorke) 2021年9月28日
あってるか知らんけど少なくとも思ってることは言語化できたぞ pic.twitter.com/SgwUodzUat
発表素材の一部をつぶやいたら思った以上の反響がありました, これは行けるんじゃね?, 的な.
というわけで, このエントリーでは
- データサイエンティストが一生懸命試行錯誤して育てたJupyter notebookに書かれた何かを元に
- エンジニアがこれまた試行錯誤してプロトタイピングしたりプロダクト開発したりっていう作業をする
- ...というチームワークにおいて, 「いい感じにプロダクトを作って世に出す」為に大切な事is何🤔
という話をコードの実例(PythonのStreamlitで書かれたプロトタイプなWebアプリ)を踏まえて紹介します.
TL;DR
- PoCからプロダクト開発というフェーズに変わる間にコード分割・テスト・リファクタリングをやると良き(開発スピード&プロダクトの質をいい感じにするため)
- データサイエンティスト・エンジニアで強みは違うので協業してこの辺をいい感じにまとめると良いのではないでしょうか
おしながき
エンジニアとデータサイエンティストの分水嶺もとい, 汽水域
本題に入る前にちょこっと小咄を.
「よっしゃAIでなんかやるやで, DXやー!」みたいなプロジェクトがあったとして, 大抵の場合下図の様に進めるんじゃないかなと思います.

- 何かのアイデアを元に企画が爆誕
- その企画が実現可能か? PoC(Proof of Concept)という名の実験がはじまる
- 実験結果はプロジェクトのステークホルダーに見せる必要がある. ここでMVP(Minimum Vaiable Product)の開発とレビューが納得行くまで(時間・お金が途絶えるまで)続く
- MVPでいい感じになる(もしくはどこかで妥協する)と本プロダクトの開発がスタート
- プロダクトを世に出す. 生の声がフィードバックとして戻ってくる
- フィードバックを元に成熟するか, はたまたピボットという方針転換(もしくは死)が入るかさあどっち?
そんなフロー(と部分的なイテレーション)が続くんじゃないかなと思います.
その中で「データサイエンティストが主となる」「エンジニアが主となる」フェーズがどこになるか?をマーキングすると,
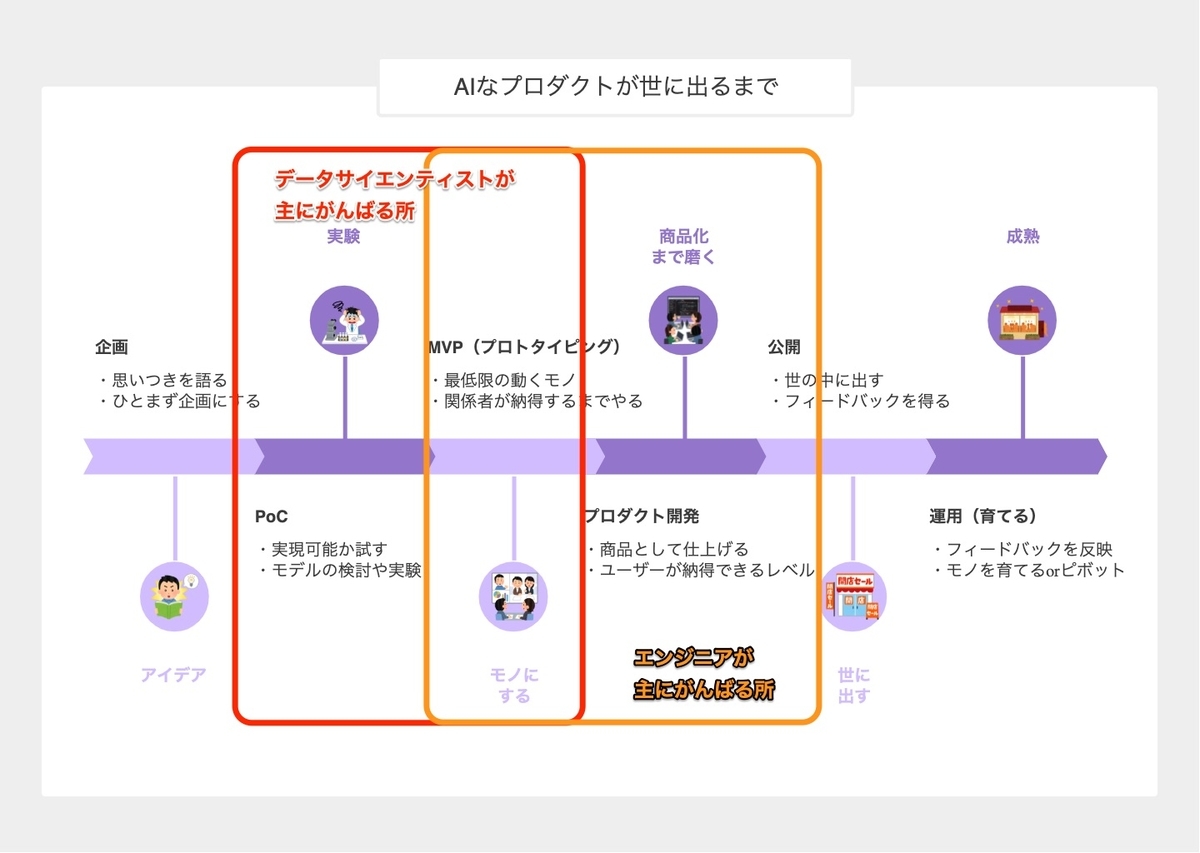
その企画が実現可能か? PoCという名の実験がはじまる というPoC(上記の2.)はデータサイエンティストが主役で, 本プロダクトの開発がスタート というガチの開発(上記の4.)はエンジニアが主役というのは非常にわかりやすい(異論も少なそう)ですが,
実験結果はプロジェクトのステークホルダーに見せる必要がある. ここでMVP(Minimum Viable Product)の開発とレビューが納得行くまで(時間・お金が途絶えるまで)続く
このフェーズが実は微妙な立ち位置にあって,
- データサイエンティストはPoCでやったことをJupyter notebookやスライドでプレゼンするとかは得意(むしろできないと職業データサイエンティストとして微妙)だが, エンジニアがプロダクト開発する前に「MVPつくるのに必要だから動くコードください」と言われると困っちゃうことがある
- エンジニアは(一定のレベルを超えてる人なら)その場のデータなり仕様で紙芝居レベルのアプリは作れる(むしろ作れるぐらいになるのが職業エンジニアとして理想)が, 学習モデルをどう使うとか実験結果云々の部分にどこまでコミットメントできるかってなると難しいよね
という問題が発生します(個人およびチームが意識している・していないは抜きにして).
問題の例としては,
「ワイが作ったモデルをエンジニアがうまく扱ってくれない(想定してない動き方になってる, 壊れてるじゃん)」
「データサイエンティストが書いたコード動かない・汚くて読めない(テストぐらい書けや)」
とかそういうやつです, きっと他にもあるでしょう(私もいくつか心当たり&酸っぱい思い出があります)
もっとも, 両方の役割を一気通貫に自力でやれるハイブリッドなエンジニア(データサイエンティスト)も存在する(現に私はその一人のはず)のですが, 都合よくそういう人が常にいるなんてことはほぼないと思います*2.
だいぶ前置きが長くなりましたが, 言いたいことはただ一つで,
AIプロジェクトの役割分担として, 「データサイエンティスト」「エンジニア」は別れてアサインされる事が多いかもですが, この両者に「分水嶺」は存在せず, むしろどこかで入り交じる「汽水域」が存在する
というのが, 自分の考え(このブログエントリーのモチベーション)だったりします.
今回のサンプル
じゃあそんなエンジニアとデータサイエンティストが存在するMVPという名の汽水域で何をするか?
ですが, それに向けてのサンプルを交えながら「僕が考えたさいきょうのエンジニア×データサイエンティストのコラボ例」を紹介します.
サンプルはこれです.
#pyconjp 2021の発表ネタ進捗です, 土曜日の #pyhack 続き
— Shinichi Nakagawa / 中川 伸一 / Senior Engineer (@shinyorke) 2021年9月20日
コード見せながら発表やりたい(=AIワクチンの奴はお見せできない)ので, しょうもないプロトタイプを作りました⚾
このStreamlitアプリがそのうちいい感じのWebアプリになります
ちなみに予測精度は期待しないで欲しい(玩具レベルです) pic.twitter.com/Xsn9MAPbnk
PyCon JP 2021のために作った, Streamlitでのサンプルアプリケーションです.
最初のコードはこんな感じです, app.py というスクリプトでStreamlitのアプリケーションとして動いています.
import streamlit as st import csv # フラグ from enum import Enum class AtBat(Enum): READY = 0 HOME_RUN = 4 OUTS = -1 atbat = AtBat.READY throws = { '右': 'R', '左': 'L' } # 球種を読み込む pitch_types = {} with open('dataset/pitch_type.csv', 'r') as f: reader = csv.DictReader(f) for r in reader: if r['pitch_name'] == 'Curveball': # 何故かダブってる pitch_types['カーブ'] = 'CU' elif r['pitch_name'] == 'Fastball': # 判定不能なので飛ばす continue else: pitch_types[r['pitch_name_jp']] = r['pitch_type'] st.write('# オオタニサン本塁打予測 :baseball:') st.write('オオタニサンがホームランを打てるボールか占ってみよう') # サイドバーを使ってみる st.sidebar.markdown( """ # ボールを決める """ ) p_throw = st.sidebar.selectbox( "利き腕", throws.keys(), ) pitch_speed = st.sidebar.slider( '球速(km/h)', 70, 170, 150, 5 ) pitch_type = st.sidebar.selectbox( "球種", pitch_types.keys(), index=4 ) # 球種の検索用にkm/h -> mp/h変換 pitch_speed_mph = round(pitch_speed / 1.609, 1) # 入力値を一旦書き出す st.write('## 投球・球種・球速') st.write( f""" - {p_throw} - {pitch_speed} km/h({pitch_speed_mph} mph) - {pitch_type}(code:{pitch_types.get(pitch_type, 'Unknown')}) """ ) # 結果を予測する from joblib import load # sk-learnで学習済みのモデルがあるのでそれをloadする model = load('model/ohtani_hr_model_app.joblib') from dataclasses import dataclass import pandas as pd @dataclass class Form: throws: str pitch_speed_kmh: float pitch_speed_mph: float pitch_type: str def predict(form: Form) -> AtBat: df = pd.read_csv('dataset/predict_shohei_ohtani_features03_app_dataset.csv') # 欲しいデータのみに絞る df = df[df['game_date'].between('2021-08-01', '2021-11-30')] # 利き腕 df = df[df['p_throws'] == form.throws] # カーブの時は2つの種別で見る if pitch_type == 'CU': pitch_types = ('CU', 'CS') else: pitch_types = (form.pitch_type, ) df = df[df['pitch_type'].isin(pitch_types)] if len(df) == 0: # 0件だったらアウト return AtBat.OUTS # 球速で絞る df = df[df['release_speed'].between(form.pitch_speed_mph - 5, form.pitch_speed_mph + 5)] if len(df) == 0: # 0件だったらアウト return AtBat.OUTS # 予測する data = df[['a', 'b']] pre = model.predict_proba(data.to_numpy())[:, 1] # スコア結果を見て判定 for r in pre: if float(r) >= 0.042 and float(r) < 0.043: return AtBat.HOME_RUN elif float(r) >= 0.0414 and float(r) < 0.0416: return AtBat.HOME_RUN elif float(r) >= 0.038 and float(r) < 0.0386: return AtBat.HOME_RUN elif float(r) >= 0.029 and float(r) < 0.029: return AtBat.HOME_RUN return AtBat.OUTS st.write('## 結果') from PIL import Image # TODO 確率を出す if st.sidebar.button('投げる'): form = Form(pitch_type=pitch_types[pitch_type], throws=throws[p_throw], pitch_speed_kmh=pitch_speed, pitch_speed_mph=pitch_speed_mph) atbat = predict(form) if atbat == AtBat.READY: st.image(Image.open('assets/img/baseball_homerun_yokoku.png'), caption='勝負') elif atbat == AtBat.HOME_RUN: st.image(Image.open('assets/img/baseball_homerun_man.png'), caption='オオタニサン!') else: st.image(Image.open('assets/img/baseball_strike_man.png'), caption='残念') else: # リセット atbat = AtBat.READY st.image(Image.open('assets/img/baseball_homerun_yokoku.png'), caption='勝負')
コードの実態はJupyter notebookでの実験結果をそのまま貼り付けたモノで, 決してきれいとは言えないコードです.
もちろん, テストは書いていません.
途中でassert文を挟んでテストっぽくするとかもあると思いますが, 「実装とテストの分離」とか考えるとあまり良い手とも思えません.
最低限やっておくべきこと
という, 実に汚いサンプルコードをもらった時どうしますか?
色々アプローチはありますが, 私ならこうします.
コードの分割少なくともテストコードが書ける単位でパッケージ・モジュールを分割する.テストを書く・動かすunittest(標準モジュール), pytest(サードパーティ)あたりで「コードが壊れたら検知する」レベルのテストを書くリファクタリング分割したコードをより洗練されたコード・設計にして書き直す. テストがあれば「デグレードした」「エンバグしちゃった」みたいな事を防いでやれる(100%じゃないにしても無いより全然いい)
いずれもやる理由・モチベーションとしては,
- パッケージ・モジュールの分割およびリファクタリングで再構成することにより, チーム開発をしやすくしたり, コードごとの責任範囲を明確にする
- テストを用意することより, 仕様を明確にするかつ, 万が一開発作業で何かやらかした時にテストで警報できるようにする
- いずれも「開発スピード・Agility」「プロダクトのクオリティ(質)」両方を取りに行くためやる
感じです.
コードの分割
app.py にすべてが集まっているという明確な問題があるので, 少しずつばらしていく.
例えばapp.py のこの辺
import csv # フラグ from enum import Enum class AtBat(Enum): READY = 0 HOME_RUN = 4 OUTS = -1 atbat = AtBat.READY throws = { '右': 'R', '左': 'L' } # 球種を読み込む pitch_types = {} with open('dataset/pitch_type.csv', 'r') as f: reader = csv.DictReader(f) for r in reader: if r['pitch_name'] == 'Curveball': # 何故かダブってる pitch_types['カーブ'] = 'CU' elif r['pitch_name'] == 'Fastball': # 判定不能なので飛ばす continue else: pitch_types[r['pitch_name_jp']] = r['pitch_type'] st.write('# オオタニサン本塁打予測 :baseball:') st.write('オオタニサンがホームランを打てるボールか占ってみよう') # サイドバーを使ってみる st.sidebar.markdown( """ # ボールを決める """ ) p_throw = st.sidebar.selectbox( "利き腕", throws.keys(), ) pitch_speed = st.sidebar.slider( '球速(km/h)', 70, 170, 150, 5 ) pitch_type = st.sidebar.selectbox( "球種", pitch_types.keys(), index=4 ) # 球種の検索用にkm/h -> mp/h変換 pitch_speed_mph = round(pitch_speed / 1.609, 1)
この辺は入出力項目の定義であり, 本体コードからバラす(app.pyは定義をimportして使う)だけでだいぶスッキリします
# entities/__init__.py from enum import Enum class AtBat(Enum): """ 打撃結果のステータス """ READY = 0 HOME_RUN = 4 OUTS = -1 class Throw(Enum): """ 利き腕 """ R = 'R' L = 'L' class PitchType(Enum): """ 球種 """ CH = 'CH' CS = 'CS' CU = 'CU' EP = 'EP' FA = 'FA' FC = 'FC' FF = 'FF' FS = 'FS' FT = 'FT' KC = 'KC' KN = 'KN' SC = 'SC' SI = 'SI' SL = 'SL'
### interfaces/label.py # アプリケーション上で使うラベル from collections import OrderedDict # TODO フロントエンドを実装する時はいらなくなるかもしれない # 順番をちゃんと決めたいので敢えてOrderdDictで実装 THROWS = OrderedDict() THROWS['R'] = '右' THROWS['L'] = '左' # FIXME csvから読む仕様を変更した PITCH_TYPES = OrderedDict() # まっすぐ系→次に早い系→遅い系の順番で PITCH_TYPES['FF'] = '4シーム' PITCH_TYPES['FT'] = '2シーム' PITCH_TYPES['SI'] = 'シンカー' PITCH_TYPES['FS'] = 'スプリット' PITCH_TYPES['SL'] = 'スライダー' PITCH_TYPES['SC'] = 'スクリュー' PITCH_TYPES['CH'] = 'チェンジアップ' PITCH_TYPES['CU'] = 'カーブ' PITCH_TYPES['KN'] = 'ナックル' PITCH_TYPES['KC'] = 'ナックルカーブ' PITCH_TYPES['EP'] = '遅球(イーファス)'
### app.py import streamlit as st from entities import AtBat from entities.form import Form from interfaces.label import PITCH_TYPES, THROWS st.write('# オオタニサン本塁打予測 :baseball:') st.write('オオタニサンがホームランを打てるボールか占ってみよう') # サイドバーを使ってみる st.sidebar.markdown( """ # ボールを決める """ ) p_throw = st.sidebar.selectbox( "利き腕", THROWS.keys(), format_func=lambda x: THROWS[x] ) pitch_speed = st.sidebar.slider( '球速(km/h)', 70, 170, 150, 5 ) pitch_type = st.sidebar.selectbox( "球種", PITCH_TYPES.keys(), format_func=lambda x: PITCH_TYPES[x] )
ひとつのファイルから剥がすだけでもだいぶいい感じになるはずです.
テストを書く・動かす
コード分割と同時並行してテストを用意します.
例えば, 結果の予測(オオタニサンがホームランを打つか否か)をこのようなモジュールに分けたとして
### usecase/bat.py from interfaces.ml import DataFrame from interfaces.ml.model import BatterModel from entities import AtBat from entities.form import Form class Bat: def __init__(self, model: BatterModel): self.model = model def predict_hr(self, form: Form, df: DataFrame) -> AtBat: """ 本塁打かどうか予測する :param form: フォームの入力値 :param df: 予測に使うデータセット :return: 打撃結果 """ # 欲しいデータのみに絞る df = df[df['game_date'].between('2021-08-01', '2021-11-30')] # 利き腕 df = df[df['p_throws'] == form.throws] # カーブの時は2つの種別で見る if form.pitch_type == 'CU': pitch_types = ('CU', 'CS') else: pitch_types = (form.pitch_type,) df = df[df['pitch_type'].isin(pitch_types)] if len(df) == 0: # 0件だったらアウト return AtBat.OUTS # 球速で絞る df = df[df['release_speed'].between(form.pitch_speed_mph - 5, form.pitch_speed_mph + 5)] if len(df) == 0: # 0件だったらアウト return AtBat.OUTS # 予測する data = df[['a', 'b']] pre = self.model.predict_proba(data.to_numpy())[:, 1] # スコア結果を見て判定 for r in pre: if float(r) >= 0.042 and float(r) < 0.043: return AtBat.HOME_RUN elif float(r) >= 0.0414 and float(r) < 0.0416: return AtBat.HOME_RUN elif float(r) >= 0.038 and float(r) < 0.0386: return AtBat.HOME_RUN elif float(r) >= 0.029 and float(r) < 0.029: return AtBat.HOME_RUN return AtBat.OUTS
predict_hr というメソッドに対するテストがこの様に書けます.
### tests/usecase/test_bat.py import pytest from joblib import load from entities import AtBat from entities.form import Form from usecase.bat import Bat from interfaces.ml import DataFrame @pytest.fixture def usecase() -> Bat: model = load('./model/ohtani_hr_model_app.joblib') return Bat(model=model) TESTCASE = [ (Form(throws='R', pitch_speed_kmh=160, pitch_speed_mph=100, pitch_type='FF'), AtBat.HOME_RUN), (Form(throws='L', pitch_speed_kmh=150, pitch_speed_mph=93.2, pitch_type='FF'), AtBat.OUTS), (Form(throws='R', pitch_speed_kmh=145, pitch_speed_mph=90.1, pitch_type='SL'), AtBat.HOME_RUN), (Form(throws='L', pitch_speed_kmh=145, pitch_speed_mph=90.1, pitch_type='SI'), AtBat.HOME_RUN), (Form(throws='R', pitch_speed_kmh=135, pitch_speed_mph=83.9, pitch_type='SI'), AtBat.OUTS), ] @pytest.mark.parametrize('form, result', TESTCASE) def test_predict_hr( df: DataFrame, usecase: Bat, form: Form, result: AtBat ): """ ホームラン判定 :param df: データセット :param usecase: 判定モデル :param form: 入力値 :param result: 結果 """ assert usecase.predict_hr(form, df) == result
今回のケースでは書き換えで予測結果が想定の範囲外で壊れるのが一番困るので, 予測モデルが壊れた時に警報をだす(テストがfailして気がつく)程度のモノを優先して用意しています.
これがあるだけで大胆な書き換え・リファクタリングができます.
リファクタリング
Streamlitで作ったMVPは最終的にフロントエンド(Reactを予定) + バックエンド(Flask)のアプリケーションに化ける予定です.
その前にある程度関心事を分ける(フロントエンドとバックエンド, バックエンド内における役割分担)をするとこの後の工程で困ることはなさそうです.
この辺の考え方・設計アプローチはオブジェクト指向やデザインパターンなどなど, 色々ありますが今回は以下の書籍・エントリーを参考にClean Architecure風にやりました.
")
最終的なパッケージ構成はこれで
app/ ├── entities/ # 定数とか横断的に使う内部仕様・定義 ├── interfaces/ # サードパーティー・ライブラリをimportしてOKな所 ├── tests/ │ ├── dataset/ │ ├── interfaces/ │ └── usecase/ ├── usecase/ # 予測モデル・ビジネスロジック的な所(entities, interfacesからimportして色々とやる) app.py # すべてを束ねて動かす人
厳密なクリーンアーキテクチャは適用せず, 「外部・内部の棲み分け」「依存は一方方向」の原則のみ守る感じでやりました.
なお, 小汚い感じだったapp.pyはここまできれいになりました.
import streamlit as st from joblib import load import pandas as pd from PIL import Image from entities import AtBat from entities.form import Form from interfaces.view.label import PITCH_TYPES, THROWS from usecase.bat import Bat st.write('# オオタニサン本塁打予測 :baseball:') st.write('オオタニサンがホームランを打てるボールか占ってみよう') # サイドバーを使ってみる st.sidebar.markdown( """ # ボールを決める """ ) p_throw = st.sidebar.selectbox( "利き腕", THROWS.keys(), format_func=lambda x: THROWS[x] ) pitch_speed = st.sidebar.slider( '球速(km/h)', 70, 170, 150, 5 ) pitch_type = st.sidebar.selectbox( "球種", PITCH_TYPES.keys(), format_func=lambda x: PITCH_TYPES[x] ) # 球種の検索用にkm/h -> mp/h変換 pitch_speed_mph = round(pitch_speed / 1.609, 1) # 入力値を一旦書き出す st.write('## 投球・球種・球速') st.write( f""" - {p_throw}(name: {THROWS.get(p_throw)}) - {pitch_speed} km/h({pitch_speed_mph} mph) - {pitch_type}(name: {PITCH_TYPES.get(pitch_type, 'Unknown')}) """ ) # 結果を予測する model = load('model/ohtani_hr_model_app.joblib') atbat = AtBat.READY usecase = Bat(model=model) df = pd.read_csv('dataset/predict_shohei_ohtani_features03_app_dataset.csv') st.write('## 結果') # 確率を出す if st.sidebar.button('投げる'): form = Form(pitch_type=pitch_type, throws=p_throw, pitch_speed_kmh=pitch_speed, pitch_speed_mph=pitch_speed_mph) atbat = usecase.predict_hr(form=form, df=df) if atbat == AtBat.READY: st.image(Image.open('assets/img/baseball_homerun_yokoku.png'), caption='勝負') elif atbat == AtBat.HOME_RUN: st.image(Image.open('assets/img/baseball_homerun_man.png'), caption='オオタニサン!') else: st.image(Image.open('assets/img/baseball_strike_man.png'), caption='残念') else: # リセット atbat = AtBat.READY st.image(Image.open('assets/img/baseball_homerun_yokoku.png'), caption='勝負')
StreamlitのWebアプリケーションとしてのコンポーネント&振る舞いの制御とデータの入出力のみに集約できたのでいい感じになったと言えそうですし, これならエンジニアも楽に移植ができそうな気がします.
結び
というわけで, データサイエンティストとエンジニアがチームプレイでいい感じにプロダクトをつくるためには? をテーマに,
- データサイエンティストとエンジニアには汽水域がある
- コード分割・テスト・リファクタリングをやることで質とスピードを両取りする
- なんちゃってClean Architectureという一つの可能性
の話を書きました.
エンジニアはデータサイエンティストに対して, データサイエンティストはエンジニアに対して憧れや思う所がお互いあると思いますが, 「両方両取りしていい感じにやれるといいね!」ぐらいに捉えて色々チャレンジするのが良いかなって思います, 幸いにもどっちもPythonという言語を使うことが多いので. 共通言語があるのはホント強いと思います.
なお, PyCon JP 2021の発表に合わせて改めてClean Architecture風にコードを書いてみたりしたのですが,
ぼくが思うクリーンアーキテクチャ
— Shinichi Nakagawa / 中川 伸一 / Senior Engineer (@shinyorke) 2021年9月24日
とかそういうノリでFlaskのアプリケーションをクリーンアーキテクチャっぽく書いてみたのだが、ああ確かにクリーンだなっていう所と一体私は何と戦って設計してるんだ感でてきてちょっとおもしろくなってきた
コード全体の見通しは良さげ
一体私は何と戦って設計してるんだ感でてきて
ここがまあまあモヤッとしたのでもう一度クリーンアーキテクチャ読んで出直したいと思います, 微妙じゃないこれ?って部分が果たして良いのかどうか🤔
結構長くなりましたが, これがAIだかDXだか知りませんが, そんなプロジェクトの助けになると嬉しいです.
次はPyCon JP 2021で会いましょう, 最後までお読みいただきありがとうございました!
【補足】参考書籍&エントリー
「エンジニアとデータサイエンティスト」という視点の問題提起は名著「仕事ではじめる機械学習」が詳しいです.

クリーンアーキテクチャは読むといいんじゃないかなって思います.